Overview
This section provides an overview of the core platform concepts.
To learn more about the platform from an end-user perspective, take a look at our Knowledge Base.
| Concept | Description | Example |
|---|---|---|
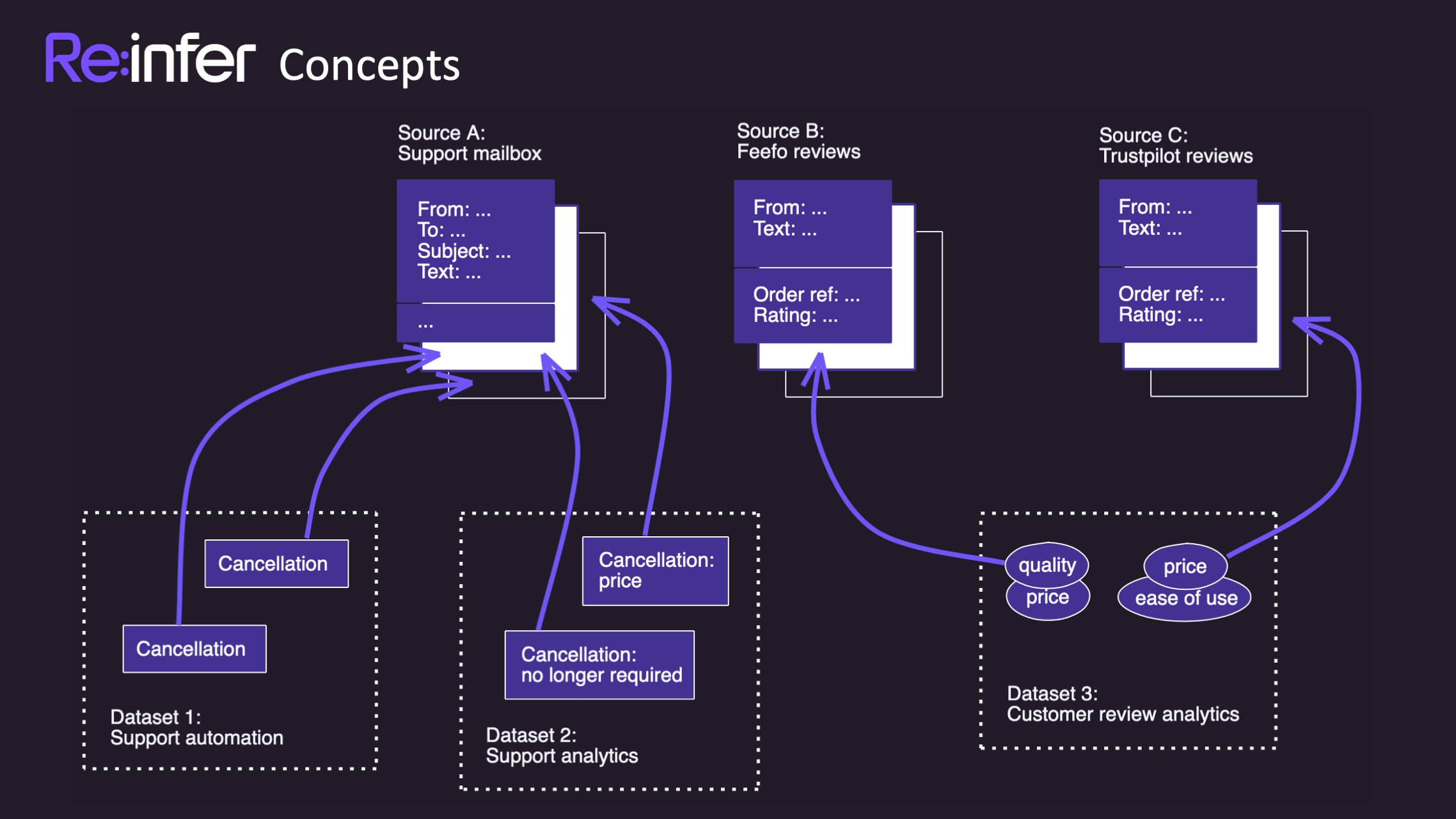
| Source | In Re:infer, data is organised in data sources, or sources. Typically a source corresponds to a channel. An email mailbox, the results of a survey or a set of customer reviews are all examples of data that can be uploaded to Re:infer as a data source. Multiple sources can be combined to build a model, so it's best to err on the side of multiple sources rather than a single monolithic source. | The diagram shows email data (Source A which contains individual emails) and customer review data (Sources B and C which contain individual customer reviews). The customer review data is split into two sources based on the data origin, but will be combined into a single dataset for the purposes of building a common model. |
| Comment | Within sources, each individual piece of text communication is represented as a comment. A comment will always have an ID, timestamp, and text body, and additional fields based on what type of data it represents. For example, emails will have the expected email fields such as "from", "to", "cc", and so on. | The diagram shows how the available comment fields are used by the various comment types. For example, in an email comment the "from" field contains the sender address, while in a customer review comment it contains the review author. The metadata fields (shown at the bottom of each comment) are user-defined. Note how we use the same set of fields for both customer review sources: since we want to combine them into a single dataset, the data should be consistent in order to ensure good model performance. |
| Dataset | A dataset allows you to label one or more sources in order to build a model. A source can be included in multiple datasets. The set of all labels in a dataset is called a taxonomy. | The diagram shows two datasets built on top of the support mailbox data, and one dataset combining the customer review data. Note that even though Dataset 1 and Dataset 2 are based on the same data, their label taxonomy is different, because their use-cases (analytics and automation) call for different sets of labels. |
| Model | The model is continuously updated as users label more data. In order to receive consistent predictions, a model version number needs to be specified when querying the model. | |
| Label | Labels are applied when training a model, and are returned when querying the model for predictions. When labels are returned as predictions, they have an associated confidence score that indicates how likely the model thinks the prediction applies. To convert the prediction into a "Yes/No" answer, the confidence score needs to be checked against a threshold, which is chosen to represent a suitable precision/recall tradeoff. | Labels are assigned by Re:infer users when training the model. The Re:infer UI helps the user label the most relevant comments, ensure that labels are applied consistently, and that enough comments are labelled to produce a well-performing model. |