Elasticsearch Integration
Re:infer offers a rich set of built-in analytics tools. However, sometimes it is necessary to join the predictions from Re:infer with data that can't be uploaded as part of Re:infer comments. In these cases a common solution is to index the Re:infer predictions and any additional data into Elasticsearch and use a tool like Kibana to drive analytics. This tutorial describes how to import Re:infer data into Elasticsearch and visualise it in Kibana.
The data used in the examples throughout this tutorial is generated dummy emails from the insurance domain.
Storing Data in Elasticsearch
First, let's define the data that we want to import into Elasticsearch. Re:infer API provides the comment text, comment metadata, predicted labels and predicted entities in a nested JSON object. Below is an example of a raw comment provided by the Re:infer API. (Note that you may see different metadata fields depending on how your data was ingested into Re:infer. You can learn more about comment object fields here.)
{
"comment": {
"id": "c7a1c529-3f57-4be6-9102-c9f892b81ae51",
"uid": "49ba2c56a945386c.c7a1c529-3f57-4be6-9102-c9f892b81ae51",
"timestamp": "2021-03-29T08:36:25.607Z",
"messages": [
{
"body": {
"text": "The policyholder has changed their address to the new address: 19 Essex Gardens, SW17 2UL"
},
"subject": {
"text": "Change of address - Policy SFG48807871"
},
"from": "CPX8460080@broker.com",
"to": ["underwriter@insurer.com"],
"sent_at": "2021-03-29T08:36:25.607Z"
}
]
// (... more properties ...)
},
"labels": [
{
"name": ["Admin"],
"probability": 0.9995054006576538
},
{
"name": ["Admin", "Change of address"],
"probability": 0.9995054006576538
}
],
"entities": [
{
"name": "address-line-1",
"formatted_value": "19 Essex Gardens",
"span": {
"content_part": "body",
"message_index": 0,
"char_start": 63,
"char_end": 79,
"utf16_byte_start": 126,
"utf16_byte_end": 158
}
},
{
"name": "post-code",
"formatted_value": "SW17 2UL",
"span": {
"content_part": "body",
"message_index": 0,
"char_start": 81,
"char_end": 89,
"utf16_byte_start": 162,
"utf16_byte_end": 178
}
},
{
"name": "policy-number",
"formatted_value": "SFG48807871",
"span": {
"content_part": "subject",
"message_index": 0,
"char_start": 27,
"char_end": 38,
"utf16_byte_start": 54,
"utf16_byte_end": 76
}
}
]
}
The schema of the raw comments returned by the Re:infer API is inconvenient for filtering and querying this data in Elasticsearch, so you should change the schema before ingesting the data into Elasticsearch. Below is an example flattened schema you can use. You should add all fields that you need for your use-case.
{
"id": "c7a1c529-3f57-4be6-9102-c9f892b81ae51",
"uid": "49ba2c56a945386c.c7a1c529-3f57-4be6-9102-c9f892b81ae51",
"timestamp": "2021-03-29T08:36:25.607Z",
"subject": "Change of address - Policy SFG48807871",
"body": "The policyholder has changed their address to the new address: 19 Essex Gardens, SW17 2UL",
// (... more fields ...)
"labels": ["Admin", "Admin > Change of address"],
"entities": {
"policy_number": ["SFG48807871"],
"address-line-1": ["19 Essex Gardens"],
"post-code": ["SW17 2UL"]
}
}
Note that a comment can have zero, one, or multiple labels, so the labels
field needs to be an array. Additionally, if one or more entity types have been
configured for the dataset, a comment will have zero, one, or more entities of
each entity type. The hierarchical label names in the raw API response are
themselves arrays (["Admin", "Change of address"]), and should be converted to
strings ("Admin > Change of address").
Fetching Data
In order to fetch the data, we recommend using the Stream API. (See here for an overview of all available data download methods.) When creating a Stream, you should set the thresholds for each label so that labels with confidence scores below the threshold are discarded. This is easiest to do from the Re:infer UI by going to the "Streams" page of a dataset. Having used the confidence scores to determine whether a label applies, you can then import just the label names into Elasticsearch. (See the Labels for Analytics section for a discussion on when we recommend to drop or keep label confidence scores.)
Entities do not have confidence scores so no special handling is required.
When creating a Stream, you specify a model version. This model version is used to provide predictions when fetching comments from the Stream. Even as users continue training new model versions in the platform, your Stream will use the model version you specified, providing you with deterministic results.
To upgrade to a new model version, you have to create a new Stream which uses that model version, then update your code to use the new Stream. (For this reason, we recommend that you make the Stream name configurable in your code.) To ensure that analytics using predictions stay consistent, you should re-ingest predictions for historical data using the updated model version. You can do that by resetting the Stream to the timestamp before your oldest comment, and re-ingesting the data from the start.
Visualizing Data in Kibana
Once you indexed the data in Elasticsearch, you can start building visualisations. This section provides simple examples for a number of common visualisation tools in Kibana.
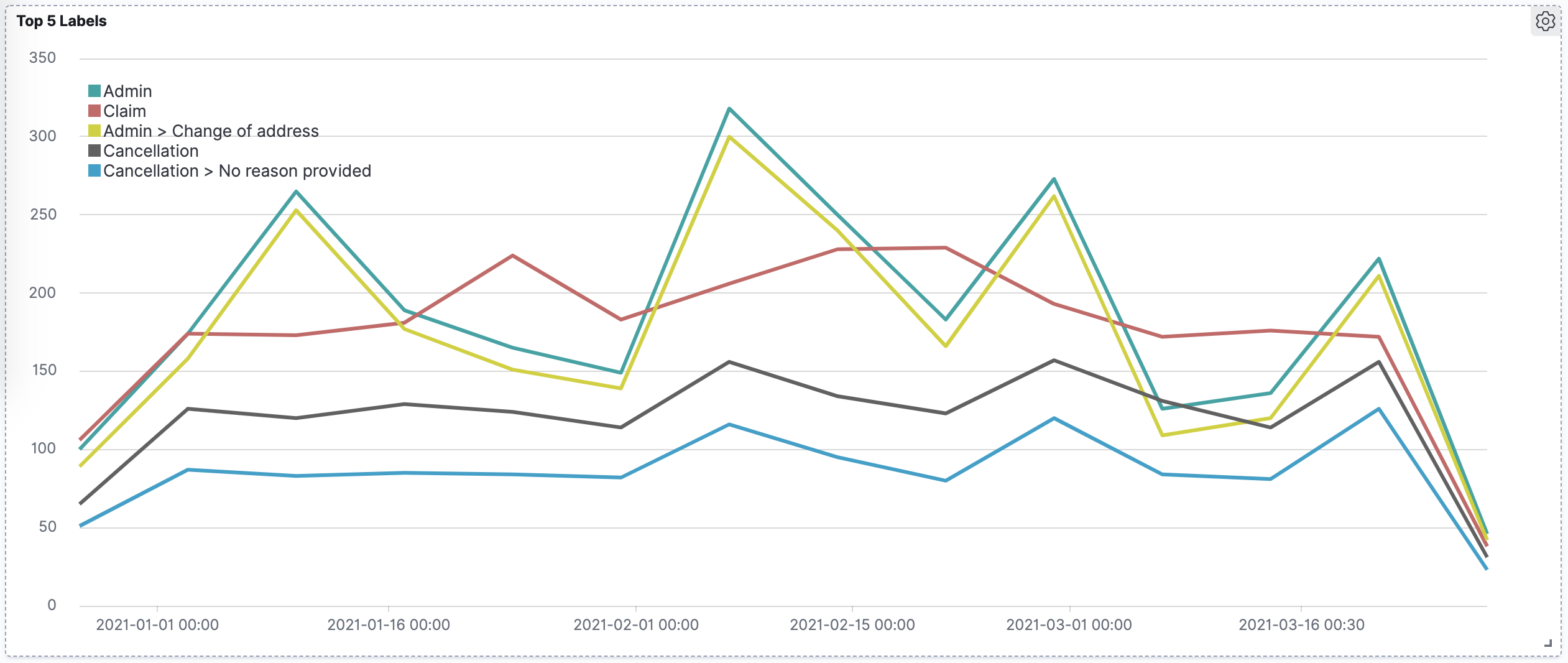
Timelion
You can use the following expression to produce a plot of top 5 most common labels over time. Note that this shows both top-level category and subcategory labels.
.es(index=example-data,split=labels:5,timefield=@timestamp)
.label("$1", "^.* > labels:(.+) > .*")
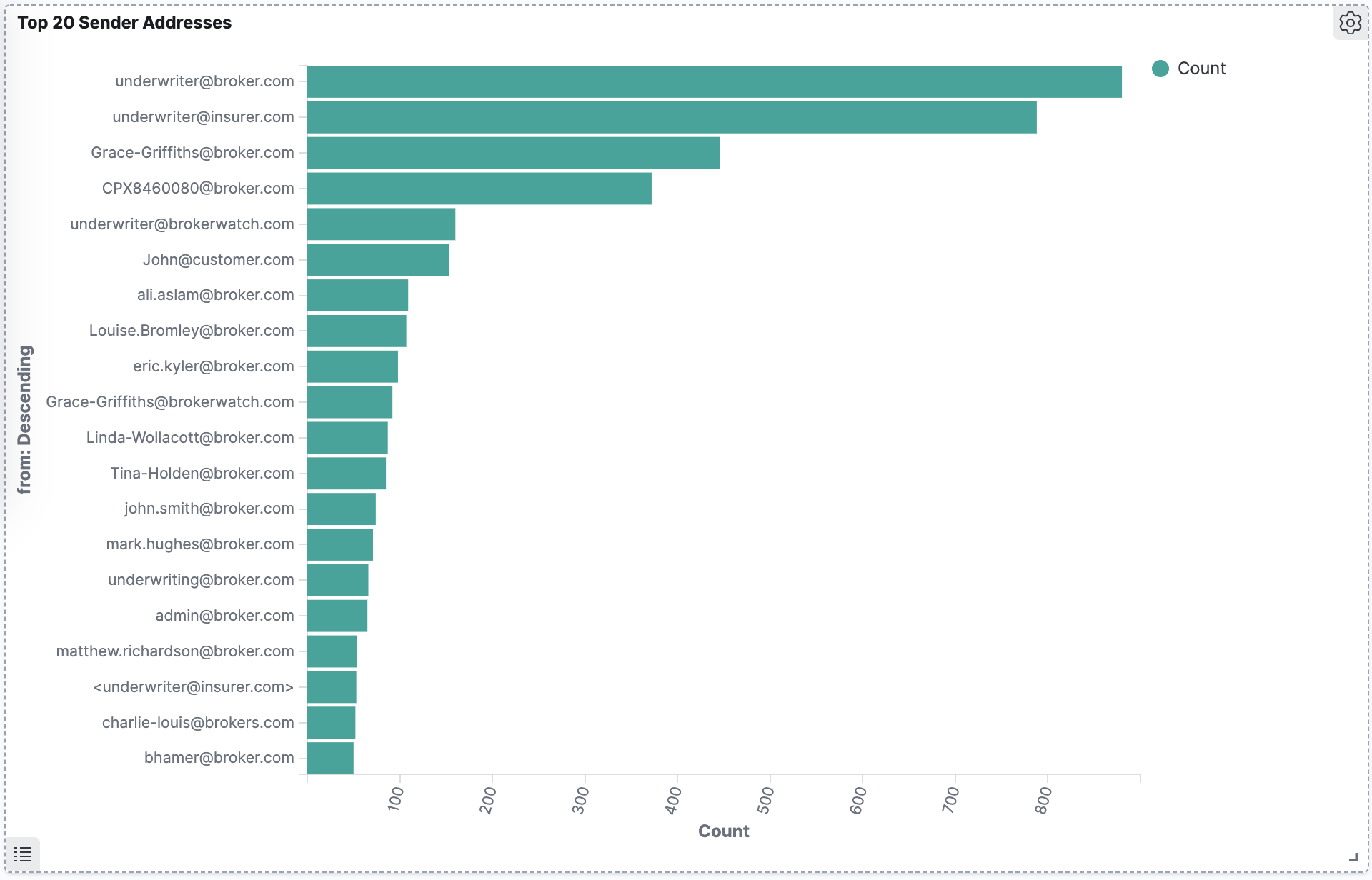
Bar Chart
This bar chart shows top 20 sender email addresses in the dataset. Sender and recipient email addresses are part of comment metadata in email-based datasets.
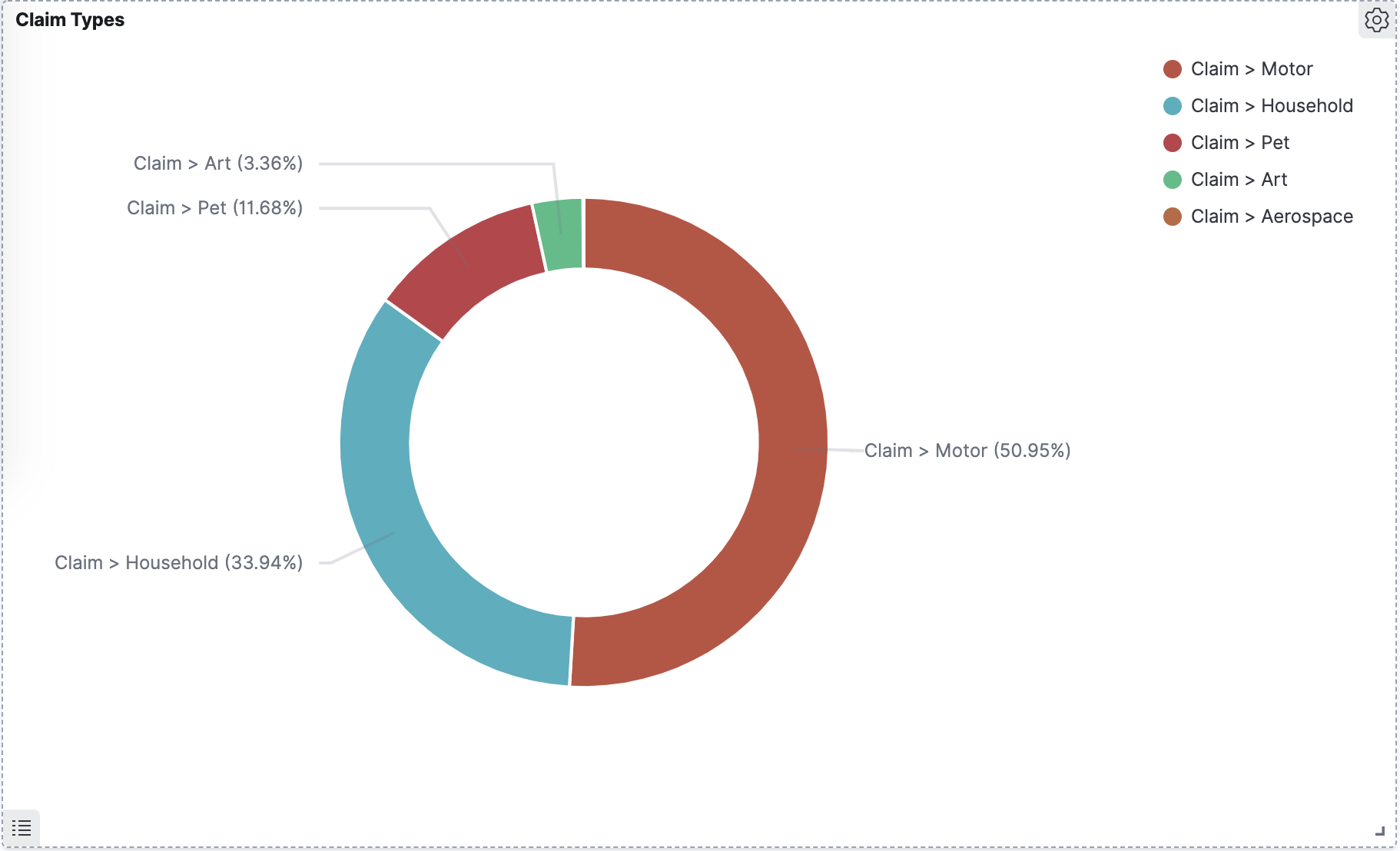
Pie Chart
This pie chart shows subcategory labels under the top-level "Claim" label. The label categories are defined by the user training the model.