
When it comes to leveraging the power of NLP and ML to automate processes, obtain better analytics and gain a deeper understanding of the conversations a company has, the first decision is usually whether to buy a solution, or build your own.
This post compares the performance and design philosophy of the Re:infer platform against one of the strongest cloud NLP solutions out there, Google's AutoML.
We hope to provide some insights into the process of using a dedicated enterprise communications intelligence product compared to making use of a more general-purpose tool, and what trade-offs one can expect.
Design philosophy
Re:infer and Google AutoML are both solutions that require the user to create an annotated training dataset that associates labels to conversations. The quality of the training data determines the quality of the predictions returned from that trained model.
The key to high quality training data is to apply labels consistently and accurately represent the domain you want to make predictions about.
The first major difference between Re:infer and Google AutoML is the design philosophy around how the product should be used.
Labelling tasks vs Active learning
The AutoML flow is to create a labelled dataset offline, which is uploaded and used to train a model. Labelling a dataset is an expensive operation that requires a lot of upfront work. How the labels are produced is out of scope for AutoML, but one possible solution is to outsource labelling to 3rd parties. Google provides Labelling tasks to this end, which are integrated with AutoML, or one could use Amazon's Mechanical Turk.
This is suboptimal for a few reasons
- Third party access is often a non-starter for sensitive internal conversations.
- It might not be desirable to outsource labelling to people who do not have the relevant insight required to fully capture the intricacies of a company's communications
- Contextual knowledge of the domain is key for high quality training data. For example, anyone can label images of cats and dogs, but less so emails from a post-trade investment bank ops mailbox, for that one needs Subject Matter Experts (SMEs).
At Re:infer we encourage people to upload a large amount of unlabelled data and use our active learning to create the labelling interactively. We believe that interactive data exploration and labelling is key to building a set of labels that truly capture all the interesting information and nuance that live in a company's conversations at the right level of granularity.
Of course, if you already have a large annotated dataset that you would like to use as a starting point, you can use our cli tool to upload the labelled dataset as well.
Waterfall and Agile model building
These two design philosophies are reminiscent of the Waterfall and Agile software development models. Where the former splits a project into sequential chunks, the latter allows for more flexibility and encourages re-evaluating priorities.


If a large labelled dataset is required upfront, then the first step is deciding what labels/concepts are going to be captured by the NLP model. Crucially, this decision needs to happen before any substantial data exploration.
An interactive approach opens the door to discovering new concepts as you label the dataset. Existing concepts can be fleshed out, or entirely new ones that had previously gone unnoticed may be discovered. If SMEs discover new concepts that were not captured by the requirements, the Waterfall model does not allow for adapting and incorporating this new information, which ultimately leads to worse models.


In the world of machine learning, where models can often fail in unexpected ways and model validation is a difficult process, the Waterfall method might be too brittle and have iteration times that are much too long to reliably deploy a model to production.
AutoML provides some help for how to improve a model, by surfacing false positives and false negatives for each label. Re:infer provides a set of warnings and suggested actions for each label, which allows users to better understand the failure modes of their model and thus the fastest way to improve it.
Data models
Another axis along which AutoML and Re:infer differ is the data model they use. AutoML provides a very general-purpose structure for both inputs and targets. Re:infer is optimised for the main communication channels mediated by natural language.
Semi-structured conversations
Most digital conversations happen in one of the following formats:
- Emails
- Tickets
- Chats
- Phone calls
- Feedback / Reviews / Surveys
These are all semi-structured formats, which have information beyond just the text that they contain. An email has a sender and some recipients, as well as a subject. Chats have different participants and timestamps. Reviews might have associated metadata, such as the score.
AutoML has no canonical way to represent these semi-structured pieces of information when uploading training examples, it deals solely with text. Re:infer provides first-class support for email structure, as well as arbitrary metadata fields through user-properties.
As shown in the example below, enterprise emails often contain large signatures and/or legal disclaimers that can be much longer than the actual content of the email. AutoML has no signature stripping logic, therefore we used Re:infer to parse out the signatures before passing them to AutoML. While modern machine learning algorithms can handle the noise due to signatures quite well, the same cannot be said for human labellers. When trying to parse an email for any labels that apply and discern interesting themes, the cognitive load of having to ignore the long signatures is non-negligible and can lead to poorer label quality.
Related concepts
Concepts within enterprise conversations are rarely independent, it is often
more natural to try grouping labels into a structured label hierarchy. For
instance, an e-commerce platform might want to capture what people think of
their delivery, and create some sub-labels such as Delivery > Speed
Delivery > Cost Delivery > Tracking. For finer-grained insights, further
breakdowns are possible such as Delivery > Cost > Free Shipping
Delivery > Cost > Taxes & Customs.
Grouping labels into a hierarchy allows users to have a clearer picture of what
they are labelling and have a better mental model for the labels they are
defining. It also naturally allows better analytics and automations since labels
are automatically aggregated into their parents. In the previous example, we can
track analytics for the top-level Delivery label without needing to explicitly
do anything about the child labels.
AutoML does not provide support for structured labels, instead assuming complete independence between labels. This is the most general-purpose data model for NLP labels, but we believe it lacks the specificity required to optimally work with semi-structured conversations.
In addition to label structure, the sentiment of a piece of text is often interesting for feedback or survey analysis. Google provides a separate sentiment model, which allows users to use an off-the-shelf sentiment model which will give a global sentiment for the input. However for complex natural language, it's quite common to have multiple sentiments simultaneously. For instance, consider the following piece of feedback:
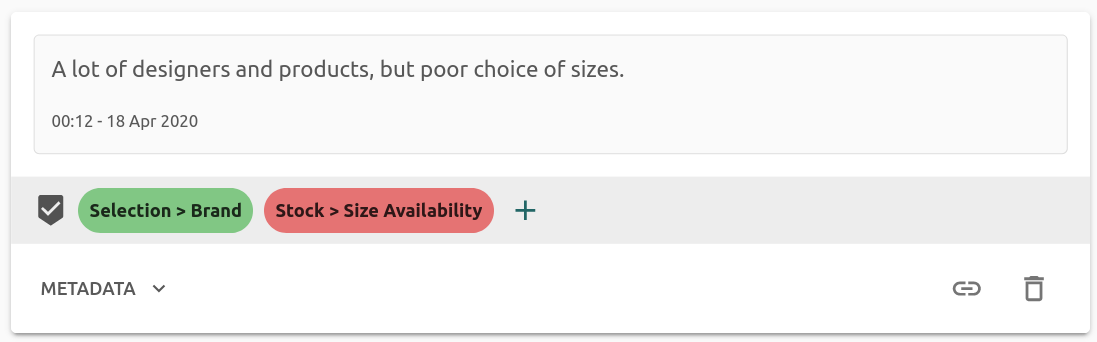
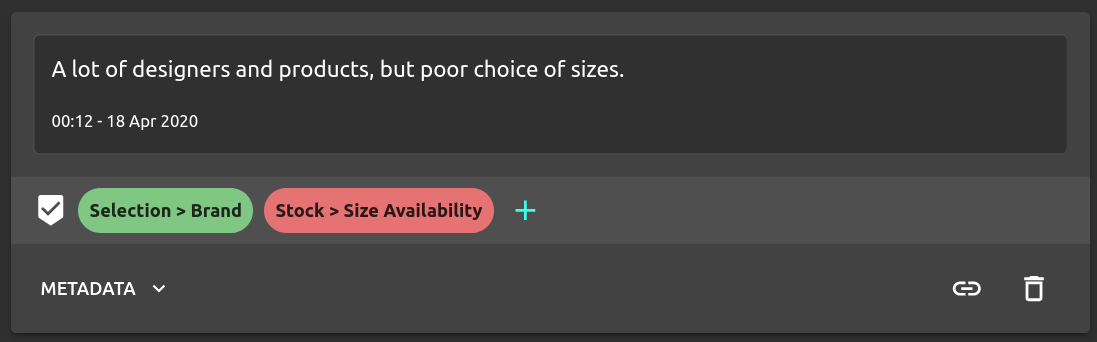
Defining a global sentiment is difficult since there are two concepts of different polarity being expressed in the same sentence. Re:infer provides per-label sentiment exactly to address this issue. The feedback above can be labelled as being positive about election, but negative about the availability of stock, thus capturing both emotions and what they relate to.
While it is possible to do something similar in AutoML by creating a Positive
and Negative version of each label, there is no way to indicate that these are
two versions of the same label, which means one would need to label twice as
much data.
Identical inputs
One other interesting observation is around the deduplication of inputs. In general, when validating a machine learning model, it is vital to preserve rigorous separation between train and test sets, to prevent data leakage, which can lead to over-optimistic performance estimates, and thus surprising failures when deployed.
AutoML will automatically deduplicate any inputs, warning the user that there are duplicated inputs. While the right approach for a general-purpose NLP API, this is not the case for conversational data.
Many emails that get sent internally are auto-generated, from out-of-office messages to meeting reminders. When analysing the results of a survey, it is entirely possible for many people to answer the exact same thing, especially for narrow questions such as
Is there anything we could do to improve? → No.
This means that a lot of these duplicate inputs are legitimately duplicated in the real-world distribution, and evaluating how well the model performs on these well known, strictly identical, inputs, is important.
Experiments
Now that we have discussed the top-level differences, we wish to evaluate the raw performance of both products to see which one would require less effort to get a production-ready model deployed.
Setup
We aim to make the comparison as fair as possible. We evaluate performance on three datasets that are representative of three core enterprise NLP use-cases
| Size | Assigned Labels | Unique Labels | |
|---|---|---|---|
| Investment Bank Emails | 1368 | 4493 | 59 |
| Insurance Underwriting Emails | 3964 | 5188 | 25 |
| E-Commerce Feedback | 3510 | 7507 | 54 |
We processed the data as follows
- Data Format. For Re:infer we use the
built-in email support. AutoML expects a
blob of text, so in order to represent the email structure we used the format
Subject: <SUBJECT-TEXT> Body: <BODY-TEXT> - Signature Stripping. All email bodies were preprocessed to strip their signatures before being passed to the machine learning model.
Given that AutoML labelling tasks are not applicable to confidential internal data, we use labels annotated by SMEs with the Re:infer active learning platform to create the supervised data we will use to train both models.
We chose these datasets because of their representative nature and didn't modify them once we saw initial results, to prevent any sampling bias or cherry-picking.
We keep a fixed test set that we use to evaluate both platforms against, and train them both with the exact same training data. AutoML requires users to manually specify training and validation splits, so we randomly sample 10% of the training data to use as validation, as is suggested by the AutoML docs.
Metrics
The Re:infer validation page helps users understand the performance of their models. The primary metric we use is Mean Average Precision. AutoML reports Average Precision across all label predictions, as well as Precision and Recall at a given threshold.
Mean Average Precision better accounts for the performance of all labels, since it is an unweighted average of the performance of individual labels, whereas Average Precision, Precision and Recall capture global behaviour of the model across all inputs and labels, and thus better represent the commonly occurring labels.
We compare the following metrics:
- Mean Average Precision The metric used by Re:infer, which is the macro-averaged precision across labels
- Average Precision The metric used by AutoML, which is the micro-averaged precision across all predictions
- F1 score Precision and Recall alone are not meaningful, since one can be traded for the other. We report the F1 score, which represents performance for a task where precision and recall are equally important.
Interested readers can find the full Precision-Recall curves in the relevant section.
Results






Re:infer outperforms AutoML on every metric on all of the benchmark datasets, on average by 5 to 10 points. This is a clear indication that a tool specialised to learn from communications is more adapted for high-performance enterprise automations and analytics.
Since AutoML is built to handle general-purpose NLP tasks, it has to be flexible enough to adapt to any text-based task, to the detriment of any specific task. Furthermore, like many off-the-shelf solutions that leverage transfer learning, the initial knowledge of AutoML is focused more on everyday language that is commonly used on social media and news articles. This means that the amount of data needed to adapt it to enterprise communication is much larger than a model whose primary purpose is dealing with enterprise communication, like Re:infer, which can leverage transfer learning from much similar initial knowledge. In terms of real-world impact, this means more valuable SME-time spent labelling, longer time before deriving value from the model, and higher adoption cost.
Low-data regime
In addition to the full dataset, we also wish to evaluate performance of models trained with little data. Since collecting training data is an expensive and time-consuming process, the speed at which a model improves when given data is an important consideration when choosing an NLP platform.
Learning with little data is known as few-shot learning. Specifically, when trying to learn from K examples for each label, this is usually noted as K-shot learning.
In order to evaluate few-shot performance, we build smaller versions of each dataset by sampling 5 and 10 examples of each label, and note these as 5-shot and 10-shot datasets respectively. As we mentioned earlier, Re:infer uses a hierarchical label structure, which means we cannot sample exactly 5 examples for each label since children cannot apply without their parents. Thus we build these datasets by sampling leaf labels in the hierarchy, so the parents have potentially more examples.
These samples are drawn completely at random, with no active learning bias that might favour the Re:infer platform.
Since AutoML does not allow users to train models unless all labels have at least 10 examples, we cannot report 5-shot performance






In the low-data regime, Re:infer significantly outperforms AutoML on most metrics for all tasks. We observe that 5-shot performance for Re:infer is already competitive with 10-shot AutoML performance on most metrics.
Having an accurate model with few labelled training points is incredibly powerful since it means humans can start working collaboratively with the model much earlier, tightening the active learning loop.
The one metric where AutoML has higher performance is Mean Average Precision for 10-shot performance for Customer Feedback, where AutoML outperforms Re:infer by 1.5 points.
Since AutoML is a general-purpose tool, it works best for data that is prose-like, and customer feedback tends to not include important semi-structured data or domain-specific jargon that a general-purpose tool would struggle with, which might be a reason why AutoML works well.
Training time
Model training is a complex process, so training time is an important factor to consider. Fast model training means quick iteration cycles and a tighter feedback loop. This means that every label applied by a human results in faster improvements to the model which reduces the time it takes to get value out of the model.
| Re:Infer | AutoML | |
|---|---|---|
| Investment Bank Emails | 1m32s | 4h4m |
| E-Commerce Feedback | 2m45s | 4h4m |
| Insurance Underwriting Emails | 55s | 3h59m |
Re:infer is built for active learning. Train time is very important to us, and our models are optimised to train fast without compromising accuracy.
Training an AutoML model is ~200x slower on average compared to Re:infer.
AutoML models require orders of magnitude longer to train, which makes them much less amenable to being used in an active learning loop. Since the iteration time is so long, the best path to improving an AutoML is likely to have large batches of labelling between model retraining, which has risks of redundant data labelling (providing more training examples for a concept that is already well understood) and poor data exploration (not knowing what the model does not know makes it harder to achieve higher concept coverage).
Conclusion
When building an enterprise NLP solution, the raw predictive power of a model is only one aspect that needs to be considered. While we found that Re:infer outperforms AutoML on common enterprise NLP tasks, the main insights we gained were the fundamental differences in approaches to NLP these platforms have.
- Re:infer is a tool tailored to semi-structured conversation analysis. It includes more of the components required for building a model from scratch in an Agile framework.
- AutoML is a general-purpose NLP tool that must be integrated with other components to be effective. It is focused more on building models with pre-existing labelled data, in a Waterfall framework for machine learning model building.
- Both tools are capable of building highly competitive state of the art models, but Re:infer is better suited to the the specific tasks that are common in enterprise communication analysis.
Unless the exact requirements can be defined upfront, the long training times of AutoML models are prohibitive for driving interactive data exploration in an active learning loop, something Re:infer is built for.
AutoML's requirement of having 10 examples for each label before training a model means that one cannot effectively use the model to guide labelling in the very early stages, which is precisely the hardest part of a machine learning project.
Furthermore, the distributional gap between the tasks that AutoML and Re:infer expect means that the more specific tool is capable of producing higher quality models faster, due to the more focused use of transfer learning.
If you found this comparison interesting, have any comments or questions, or want to try using Re:infer to better understand your company's conversations, please get in touch at reinfer.io!
Precision-Recall curves
For deeper understanding of how the behaviour of Re:infer and AutoML models differ, top-level metrics such as Average Precision cannot provide the full picture. In this section we provide the Precision-Recall curves for all comparisons, so that readers may evaluate what Precision/Recall trade-offs they can expect given their specific performance thresholds.











