
Re:infer is a conversational data intelligence platform that enables users to discover, measure, and automate processes hidden in their communication channels.
Typical channels include emails, tickets, chats, and calls. Conversations in these domains are complex and nuanced. As a result, generic machine learning models perform poorly. Instead, Re:infer allows anyone to create custom models with little effort. No technical knowledge required.
This is an incredibly powerful approach. Models can learn complex patterns and make predictions on unseen data, just like humans. Machine learning models have even out-performed humans on some natural language tasks.
But like humans, machine learning models can also make mistakes. Estimating how often a model will be wrong is crucial for any real-world application of machine learning. Of equal importance is presenting this intuitively and highlighting the best actions to improve a model. Re:infer uses model validation to accomplish all these tasks.
How to validate a model
During model building, users create labels for topics they care about and tag examples with those that apply. The platform then trains a machine learning model to predict the correct labels for these examples.
To validate this model we compare its predictions to human annotations and look for mistakes. Comparing predictions by hand for many examples is difficult. Instead, we calculate a validation score which summarises how well a model is working. To do this for a trained model we need two things: annotations and a score.
Annotations
To check if predictions are correct we need to know the right annotations for each example. In other words, we need data points annotated by users.
We already use annotations to train the model, and we could reuse these during validation. However, like a human taking a test, machine learning models will perform better on examples they have "seen" before.
If we score a model using the data it was trained on, we may overestimate the model quality. This gives a misleading picture of how well our model works (known as overfitting). Because of this, we use different data points to train and validate models.
The standard approach is to split the set of annotations into two unequal parts at random
- Training set. The set of examples used to train the model. This is normally a larger fraction, say 80% of the total annotated data
- Test set. The remaining fraction (20%) of examples used to measure model performance1.
As it comes from the same source, the test set is similar to the training set. When we check performance on the test set we simulate the model seeing new emails, but we can compare to the true labels to get an idea of model quality.
Score
To summarize model performance as a number we need a scoring function. This function compares model predictions and human annotations and outputs a number.
Selecting a scoring function can be a difficult process. The function must match our idea of a good model, and we need to consider common pitfalls which can make scores inaccurate.
At Re:infer, we use Mean Average Precision for our scoring function. This is a robust way of measuring model performance across multiple labels and use-cases. If you're interested in finding out more, read our blog post on metrics.
Validation with Re:infer
With these two components, validation is simple. All we need to do is get model predictions for the test set then use our score to measure how well the model performs. Every time you train a new model in Re:infer, the validation process is automatically run in the background and the results are reported on the Validation page.
In fact, every time we train a new model, we actually train two models behind the scenes
- Validation model. This is trained on the training set and tested on the test set to measure performance.
- Production model. This is trained on all annotated examples (the training set AND the test set) and used to make predictions on live data. This model may be different to the validation model as it is trained on more data, but both models share many training examples so any differences will be small. As a result, validation model performance is a good estimate of production model performance.
With this approach, the model used for downstream applications has seen as much data as possible.


Why you should care about validation
Validation is a vital part of developing effective machine learning models and provides many benefits to users. In case you're not convinced, here are three key reasons you should care.
Known unknowns
Validation tells you how well your model performs, but it also highlights situations where your model may struggle. These situations can surface for any number of reasons; from changing trends in live data to inconsistent labelling across users and teams. It's important that model validation is interpretable so you know about problems as they arise and can fix them quickly.
Validation allows you to inspect data points which your model is unsure about. You can then improve your model in this area or build robustness into any downstream process. This means you can be confident your model is doing exactly what you want it to do, and there are no nasty surprises.
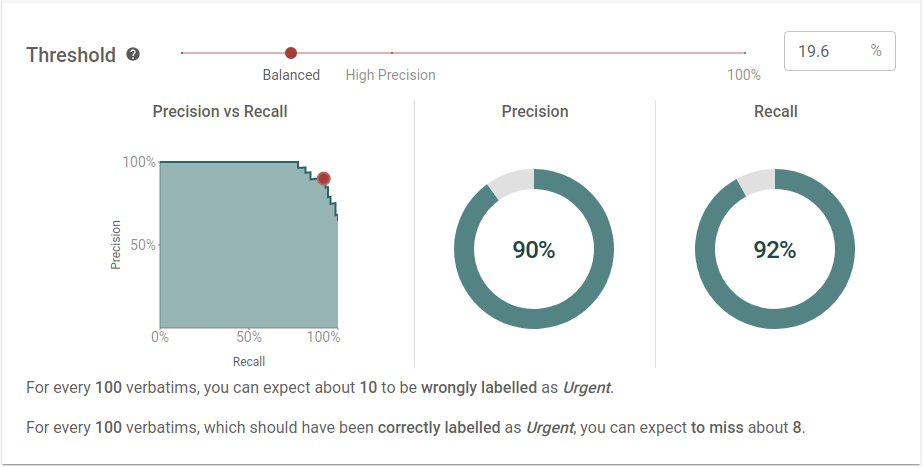
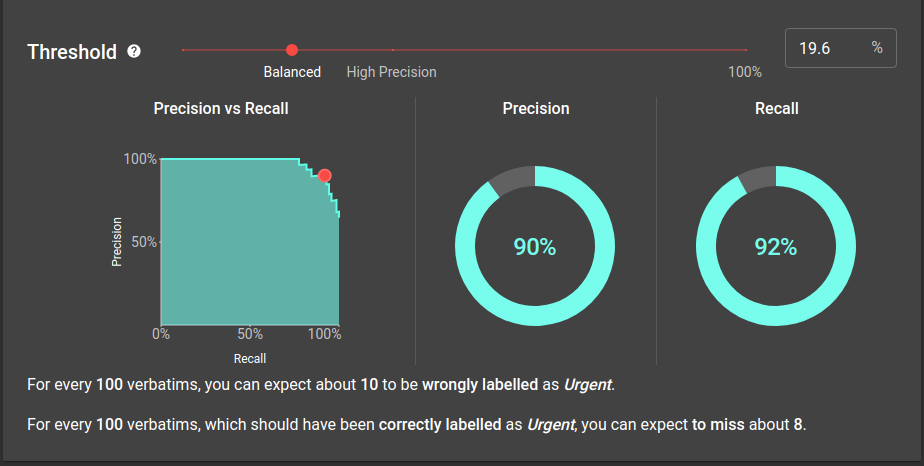
No experience required
There are many hazards when training models which can often be difficult to diagnose. Thankfully, our validation process means you don't have to be a data scientist to build great models.
When we validate a model, we don't just return a single score. Instead, we calculate a model rating. This includes the model validation score as well as other factors, such as patterns in the unreviewed data and skew in the annotated examples.
Model ratings give detailed feedback on performance and clear instructions on how to improve. Users can focus on leveraging their domain knowledge to solve problems without collaborating with development teams or AI experts. Re:infer will guide you through every step of model development.
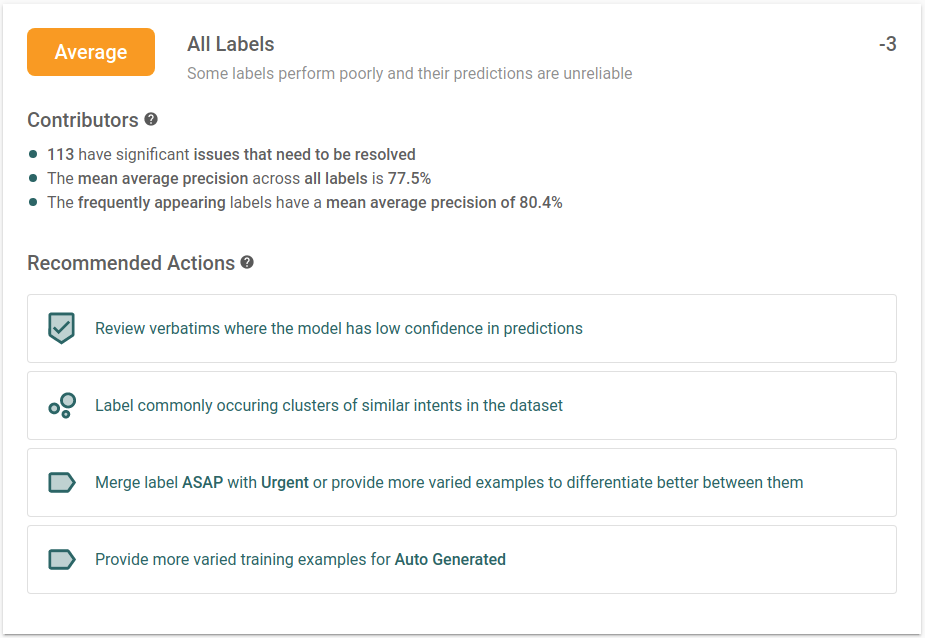
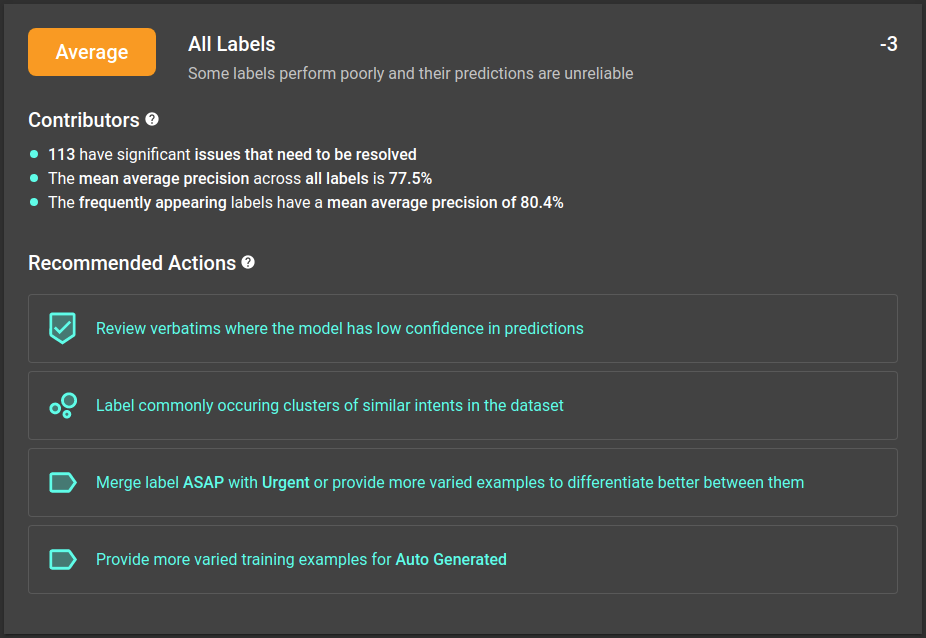
Faster feedback, better models
Most machine learning models are updated infrequently, and validated once before deployment. At Re:infer we take a different approach.
Instead of waiting a long time between updates, we continuously train and validate new models. This means the model is always applicable to the current state of the data, and validation results are up to date.
Rapid feedback minimises model iteration time. Any drops in performance can be fixed as quickly as possible, and users never waste time addressing outdated feedback. Re:infer's agile validation process allows users to build high quality models in less time.
Summary
- Validation is used to score models and ensure good performance on unseen data.
- Models are scored on unseen data to accurately estimate their performance and avoid overfitting.
- We use model ratings to give detailed feedback so you can rapidly fix problems and be confident that your model is doing exactly what it should be.
1 In Machine Learning literature you may have seen data split into three sections: train, validate, and test. The validation set is used for tuning the model and the test set is evaluated once with the final model to measure performance. At Re:infer, we use k-fold cross-validation on the train set to tune the model, and our "validation" scores are calculated on the test set with the final model. This makes them equivalent to test performance in ML literature.