
Training a machine learning model from scratch is hard. It is a common misconception that building the model itself is the hardest part of training a model. In reality, the data collection and annotation process is far harder than people assume.
Determining what concepts the model should learn, collecting the data, having subject-matter experts (SMEs) annotate it, making sure they are consistent to ensure annotation quality, are all processes that are time-consuming and require collaboration between multiple teams and stakeholders.
This substantial time-sink delays the time to value you should be getting from machine learning. Furthermore, it’s often a barrier to using ML-driven value through analytics and automation in the first place. The difference between perceived and actual difficulty of data annotation leads to ML projects failing due to misestimated time constraints. If using machine learning is a journey, this is like leaving without a map, getting lost and giving up before reaching the destination.
In this blog post, we’ll talk about one way to mitigate these issues: Active Learning, which sits at the heart of the Re:infer platform.
What is Active Learning?
Active Learning in a nutshell
At its core, Active Learning is a set of methods that aim to reduce the amount of data required to train a machine learning model. It’s an iterative process where human annotators and the model work collaboratively. The fundamental idea is that not all data points are equally informative. Intuitively, a good tutor can build a curriculum that works best for a student, as opposed to having them work through the entire textbook.
- Easy concepts require less data to learn well than harder ones
- If there are different ways to express the same idea, it’s more valuable to show the model a wide variety of examples rather than the same phrasing multiple times
- Once a model has confidently understood a concept, it’s much more valuable to train it on other concepts than to feed it more data that only helps to solidify its understanding
There are many specific methods for Active Learning, but they all rely on defining a notion of model uncertainty, which quantifies how confident the model is in its predictions. You can find implementations and descriptions of a wide variety of common uncertainty metrics in the modAL python library, or you can learn more about Active Learning research in this survey paper. We recommend checking them both out.
The classic Active Learning loop looks like this:


By iteratively labelling only the data points that are most informative to the model, and rapidly iterating, one can achieve significant reduction in the amount of effort required to achieve identical performance.
But that’s enough theory, let’s put this into practice.
The Reuters dataset
For demonstration purposes, we use the publicly available Reuters corpus provided by the NLTK. It is a collection of 10,788 news articles tagged with 90 categories, and any article can have one or more tags.
For instance, the following article was tagged with grain, ship and wheat.
FRENCH EXPORTERS SEE HIGHER WHEAT SALES TO CHINA
French exporters estimated that around 600,000 tonnes of French soft wheat has been sold to China for delivery in the 1986/87 (July/June) year. Around 300,000 tonnes were exported to China between July 1986 and February this year. Another 100,000 to 150,000 tonnes will be shipped during this month and around the same amount in April, they said. France sold around 250,000 tonnes of soft wheat to China in 1985/86, according to customs figures. However, certain exporters fear China may renounce part of its contract with France after being offered one mln tonnes of U.S. soft wheat under the Export Enhancement Program in January and making some purchases under the initiative.
You can find our cleaned/processed data here. Feel free to experiment with it for yourself!
A simple Active Learning comparison
Let’s compare Re:infer’s Active Learning strategy with random sampling from the training set, which is the standard baseline for data collection.
For all experiments, our setup is:
- We select the 20 most common tags and only learn those
- For our train/test split, we use the one provided by the dataset
- We report the mean and standard deviation across 10 runs
- The underlying machine learning model is exactly identical, the only difference is the labelling strategy
Both methods start with the same 100 randomly selected examples - the initial set. Active Learning needs a small amount of initial data to get reliable uncertainty estimates before we can use them to guide the training process. In practice, this initial set is usually created using Clusters in the Discover page in Re:infer, but to make the comparison as fair as possible we use the same random initial set for both methods in this post.
For Active Learning, we iteratively pick the 50 most informative examples, as estimated by the Re:infer Active Learning strategy, then retrain a model, and repeat. For the baseline we randomly sample 50 examples from the remaining unlabelled data at each iteration.
At each time step, we compare the performance of both models on the exact same test set, and use Mean Average Precision (MAP) as our primary metric.


Active Learning clearly outperforms the random baseline. The latter achieves 80% MAP after 3050 training examples, whereas the Active Learning-driven training achieves it after only 1750 examples, or a reduction of 1.7x.
We have demonstrated empirically that Active Learning can reduce the data requirements to produce a good model, but is that truly what we wish to achieve?
Rethinking the objective
We believe that the true objective of Active Learning should be to reduce the time it takes to produce a good machine learning model. This time is split between coordinating different teams and managing schedules, model development and training by data scientists, and data annotation by SMEs.
Fallacies in academic Active Learning
Most Active Learning research aims to create methods that further reduce the data requirements for a model. They usually make assumptions that are not necessarily correct in a real-world setting.
Annotators don’t take the same time to label all inputs
Aiming only to reduce the number of training points ignores the fact that the time to annotate different inputs varies dramatically, even for the same person. Inputs with longer text, or more complicated phrasing take longer to read. Inputs with more concepts take longer to annotate, because one has to keep track of many different themes while reading through the text.
There is also a cost to context-switching. Asking an annotator to label the same concept 20 times in a row will be faster than labelling 20 different concepts, since the annotator will have to constantly switch mental context and cannot get into a good labelling flow.
Looking only at the number of labelled examples can be misleading. Indeed, if an input is half as informative but ten times faster to annotate than another, annotating it is a better trade-off in terms of active SME time. Ultimately, this is the most important metric to minimise.
Annotators are not well integrated in the loop
Active Learning research assumes that asking an annotator to label an input surfaced by the latest trained model can happen instantaneously. In this world, the human annotator is tightly integrated into the Active Learning loop and is just waiting to be fed an input to annotate, like a labelling machine.
In reality, however, the SMEs responsible for annotating data are rarely the same people that control model training. Each iteration requires coordination between SMEs and data scientists to pass the data back and forth and provide access to the new model, syncing with everyone’s busy calendars.
Model retraining is not instantaneous
Since Active Learning requires many iterations to improve the model optimally, a common assumption is that retraining a model happens instantaneously, and that the only time-consuming activity is data annotation. However if model retraining is controlled by a separate data science team, or is being provided by a state-of-the-art cloud solution like Google AutoML, the time to retrain a model can actually be significant. Google AutoML estimates that training a model takes 6-24h. This is fundamentally incompatible with rapid iterations, if every time SMEs label a batch they need to wait 6h before being given the next batch then training a model will take weeks, if not months.
SMEs don’t know when to stop training
In order to establish benchmarks and produce comparable research, performance is usually benchmarked against a well-defined test set. This is necessary for academic research, but in the real world such a test set does not exist, as we start with no labelled data at all. Knowing when the model has reached sufficient performance to be used in production, and thus when SMEs can stop labelling more data and start getting value, is a difficult task.
Academic datasets have a well-known set of labels that they are trying to learn, which makes test set accuracy a good indicator of progress. In the real world, SMEs are often unsure what concepts exist within their data and discover new ones as they label. A good progress report needs to take this uncertainty into account.
Active Learning for the real world
At Re:infer we have built a product that challenges these assumptions, and takes into account the reality of training a machine learning model in a business environment with multiple stakeholders and challenging requirements.
The Re:infer UI is designed to help SMEs annotate data as quickly as possible. The UI surfaces suggested labels based on the latest models predictions, allowing users to quickly assign or dismiss predictions, instead of having to select from the entire label-set. As the model gets better, the suggestions get better, making it increasingly faster for annotators to review more data.


Assigning the first three labels for this article is much faster than the fourth, which was not suggested. The predictions also help the SME know what to expect even before they start reading, priming the context in their minds.
The second key factor is that Re:infer models are fast to train, taking two minutes or less on average. Models are trained continuously in the background, triggered by SMEs annotating data.
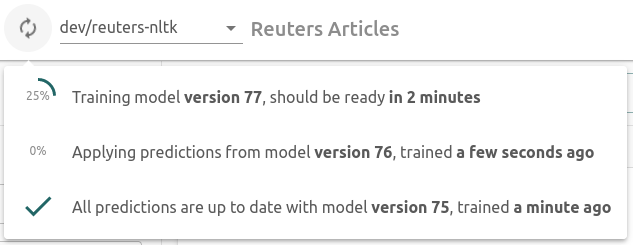
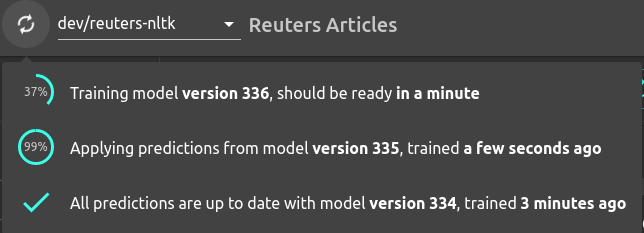
The platform is always powered by the latest available model, so while a model is training the Active Learning loop can still function using the previous model. Continuous retraining in the background means that downtime due to model retraining is effectively removed, everything is seamlessly integrated.
The Re:infer Model Rating
Re:infer’s Active Learning strategy is driven by the Model Rating. The driving idea behind it is to provide a holistic rating that is easy to understand, providing both an overview of how well the model is performing and what the best way to improve it is.


It shows four axes along which the model can be evaluated:
- Balance tracks how well the training data for a model represents the dataset as a whole
- Coverage tracks how accurately the concept taxonomy covers all concepts in the data
- All Labels tracks the predictive performance across every label
- Underperforming Labels tracks the predictive performance of the lowest performing labels. In a perfect dataset even the lowest performing labels should perform well
The last two are quite similar to test set performance used in academia, albeit modified to be estimated from the available reviewed data instead of an a-priori known test set. The first two are designed to help mitigate potential pitfalls of iterative labelling with an ever-evolving set of labels. Interested readers can learn more about them by reading our upcoming blog posts on Balance and Coverage.
We combine all these factors into a single score, the Model Rating. This tries to answer the question of when to stop training, by providing a definitive score that can be used to track progress.
Each factor recommends actions for how to improve it, as well as some indicative contributors to help understand the factor rating.
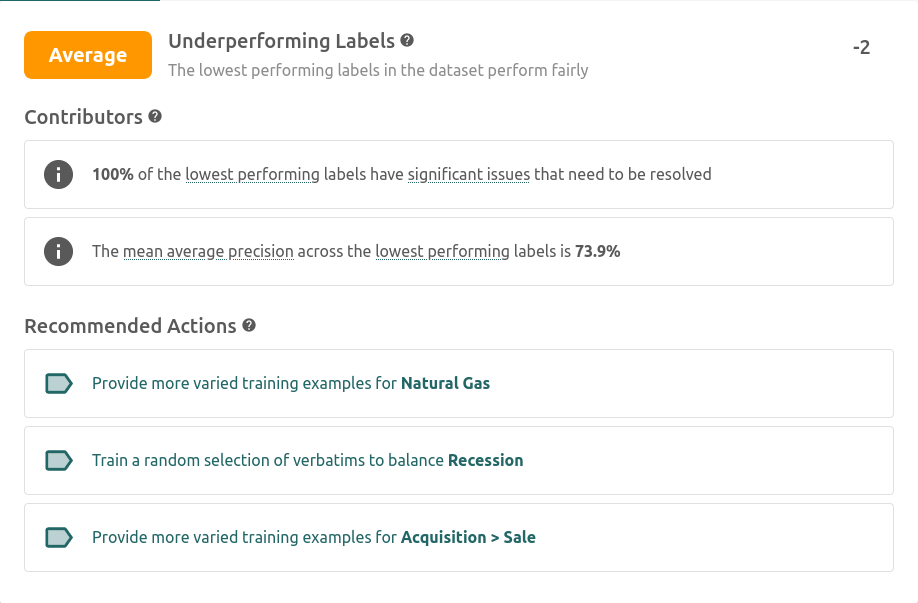
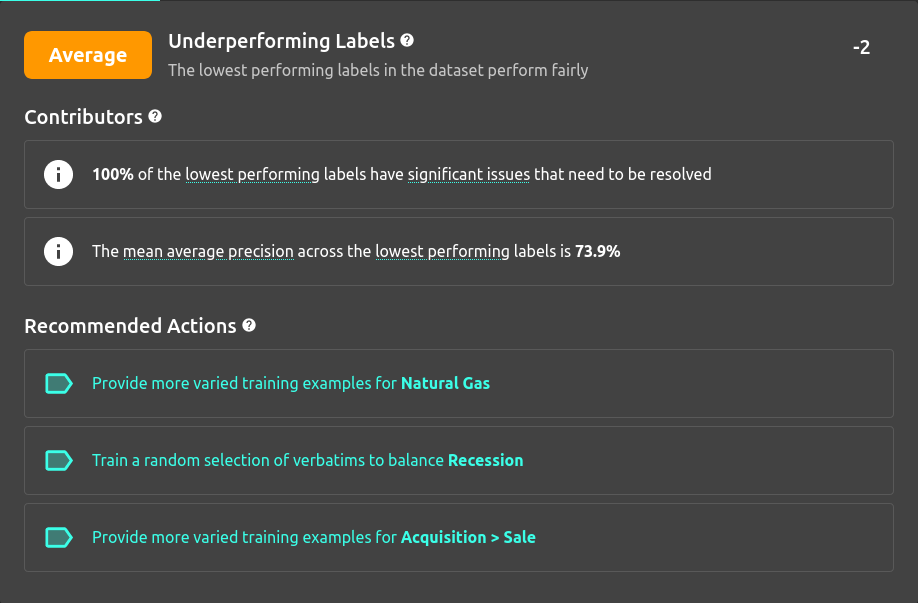
Providing a set of actions linked to what they are aiming to improve helps users better understand the areas where the model is lacking and gives them more context when labelling. Educating users about their model while asking them to improve it is a more empathetic way of labelling data, instead of treating SMEs like oracle labelling-machines. Giving them multiple options for improving the model along the axis they most care about gives them more agency and leads to a less frustrating experience.
It is better for SMEs to annotate many slightly less informative inputs with ease than get mentally exhausted from annotating very hard inputs and stop after only a few examples.
Actions are grouped so that when doing one action, SMEs are trying to improve one specific area of a model, minimising context switching, effort, frustration and time spent labelling.
Better models in dramatically less time
Let’s go back to the Reuters dataset, but reframe our earlier comparison in terms of human hours instead of data points.
How fast can one label?
In order to do this, we need to determine how long it takes to annotate an input on average. We studied our users’ behaviours as they used the platform in order to estimate this, and found that the main two factors that come into play to determine annotation speed are whether labels are predicted and whether the task involves context switching.
In the Re:infer platform, some training views such as Shuffle, Low Confidence, Recent and Rebalance involve surfacing inputs that are not grouped by any particular theme, meaning frequent context switching. Others, like Discover, Teach Label or sorting by a specific label probability, surface inputs that are all related, and thus lead to a more focused experience.
The following table shows the estimated median time per annotation in seconds broken down by these two factors.
| Assigning Manually | Confirming Predictions | |
|---|---|---|
| Context Switching | 7.10 | 2.95 |
| Focused | 5.56 | 2.66 |
We observe that confirming predictions is much faster than assigning labels manually, and that the random labelling without tooling can be over 2.5 times slower than confirming predictions in a dedicated tool! But even without predictions, a focused task is on average 22% faster than one where context switching is required.
Stay tuned for a follow-up blog post where we do a deep-dive into this data and uncover what makes or breaks a fast labelling experience.
Using this data, we can estimate the active human hours required to build a good model.
Comparing strategies by active labelling time
Let’s go back to our initial comparison. In order to fully understand the impact of different factors, in addition to the two methods we compared previously, we study three additional scenarios.
- Re:infer’s Active Learning, which we used in our previous comparison. Guided by the Model Rating, at each time step we label the first ten samples from each of the top five recommended actions before retraining the model. In reality, Re:infer models usually finish retraining before 50 new annotations are provided, so in practice the model would actually be more up to date than in our simulation.
- Active Learning without suggestions, which uses the Re:infer strategy, but not a dedicated labelling UI that speeds up annotation by surfacing predictions.
- Random sampling without suggestions, which was our baseline in the previous comparison. At each time step we randomly sample 50 of the remaining unlabelled candidates, and do not use a dedicated labelling UI.
- Random sampling with suggestions, identical to the previous strategy but augmented with a dedicated labelling UI.
- Random batch learning, as would be expected in a situation where SMEs are not tightly integrated in the Active Learning process and do not have access to adequate tooling such as the Re:infer UI. In this situation we assume that model training is a long process, and thus that labelling happens in large batches to amortise training time. At each time step, we randomly sample 1000 new inputs and annotate them.
First we study what would happen if we only looked at active SME time, when they are sitting at a computer labelling data for model training.


We observe that dedicated labelling tooling and Active Learning individually both yield substantial improvements over the random baseline. Combining Active Learning with good UX allows us to both improve data efficiency and reduce the time required to label each input, thus combining both benefits and yielding even greater speedups.
However the intermediate scenarios are somewhat artificial. In reality, a company aiming to start leveraging machine learning is likely to either buy a tool such as Re:infer that comes with both features, or build a proof-of-concept in-house that will be much closer to the Random Batch scenario. Thus for our subsequent comparisons we focus on Re:infer and Random Batch.
We benchmark the time delta between both scenarios yielding a model that reaches 80% MAP.


Re:infer yields a 3.1x speedup when compared to Random Batch labelling, allowing SMEs to achieve the required MAP in 3h instead of 9h25m. That’s the difference between one morning and one and a half business days spent labelling!
Estimating time to value
The previous estimate is still relatively optimistic, since it only looks at the time SMEs are actively labelling. While active SME time is an important factor to consider, the time-to-value of a machine learning project is also measured in wall time, or the time in days between the start of a project and delivery of a model that is worth using. When considering wall time, we need to take other factors into account.
As mentioned earlier, if provided by a third-party cloud solution such as Google AutoML, training time can take up to 24h. In a recent comparison of Re:infer’s models against AutoML, we found that training on 400-5000 examples usually took around 4h, so we’ll use that as our estimate.
Furthermore, even when using a cloud ML solution, model training needs to be triggered by an in-house data science team. In this situation, each round of labelling involves the following steps:
- Collect data from all SMEs involved in annotation
- Send the data to the data science team
- Data scientists manually check that the new data is properly formatted and that all the required fields have been filled out
- Potentially ask SMEs to fix any issues in the data
- Merge the existing data with the newly collected set
- Train a new model
- Validate performance of the new model, make sure the training run ended successfully
- Use the new model to fetch a new batch of unlabelled data to be annotated by the SMEs
- Send the data over for annotation
All these steps need to happen while coordinating between multiple teams with different priorities and schedules, which leads to lots of downtime. From our interactions with partners, we estimate each iteration to take a bare minimum of 48h, but we’ve seen it take weeks if team priorities are not aligned.
Using 48h as our average downtime due to cross-team communication, we can produce a realistic estimate of the time to value for a machine learning project.


This task can be completed in 3h with Re:infer, but without appropriate tooling it can take as long as 270h, or 89 times slower.
The difference between deriving value after half a day's work involving one person, or over two business weeks involving multiple teams, can make or break the adoption of machine learning in a company, potentially missing out on the value it can provide.
Conclusion
We have covered a few topics in this blog post, but the main takeaways are:
- Active Learning can help reduce the number of data points required to train a good machine learning model
- Active Learning research makes assumptions that are not always realistic
- By confronting those assumptions and including human annotators more in the labelling process we can dramatically reduce the time to value for a machine learning project
- Prioritising the human experience is vital for a successful Active Learning strategy
If you want to try using Re:infer to speed up adoption of machine learning-driven value for your company, please get in touch at reinfer.io.