
Re:infer's machine learning models use an architecture called the Transformer, which over the past few years has achieved state of the art results on the majority of common natural language processing (NLP) tasks. The go-to approach has been to take a pre-trained Transformer language model and fine-tune it on the task of interest.
More recently, we have been looking into 'prompting'—a promising group of methods which are rising in popularity. These involve directly specifying the task in natural language for the pre-trained language model to interpret and complete.
Prompt-based methods have significant potential benefits, so should you use them? This post will:
- Illustrate the difference between traditional fine-tuning and prompting.
- Explain the details of how some popular prompt-based methods work.
- Discuss the pros and cons of prompt-based methods, and provide our recommendation on whether or not to use them.
Background
Over the past few years, the field of NLP has shifted away from using pre-trained static word embeddings such as word2vec and GloVe towards using large Transformer-based language models, such as BERT and GPT-3.
These language models are first pre-trained using unlabelled data, with the aim of being able to encode the semantic meaning of sequences of text (e.g. sentences/documents). The goal of pre-training is to learn representations which will generally be useful for any downstream task.
Once pre-trained, the language model is typically fine-tuned (i.e. the pre-trained parameters are further trained) for a downstream task e.g. intent recognition, sentiment classification, named entity recognition, etc. The fine-tuning process requires labelled training data, and the model is fine-tuned separately for each task.
Pre-training
Although Transformers operate on sub-word tokens, this post refers to words throughout in order to keep things easier to understand.
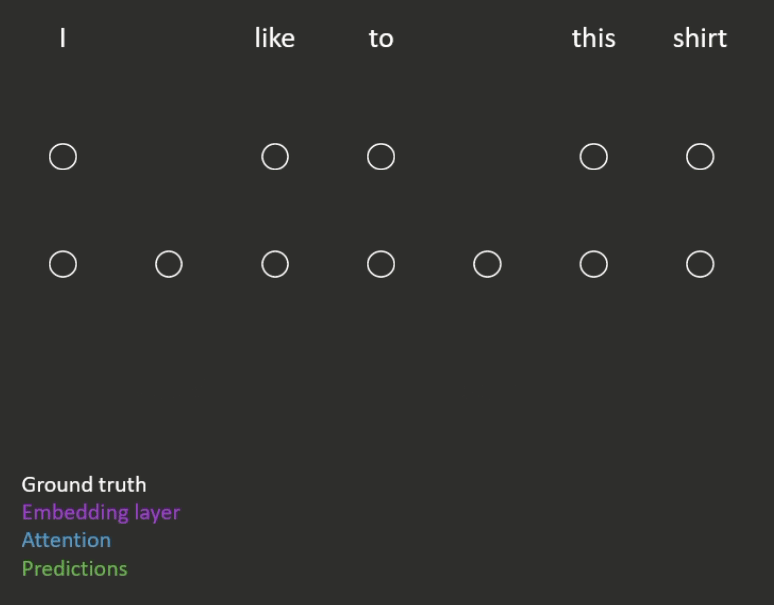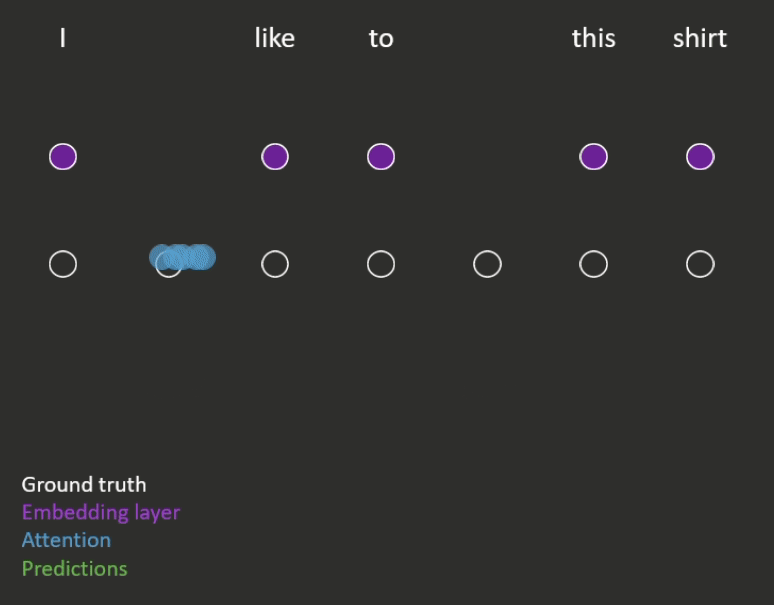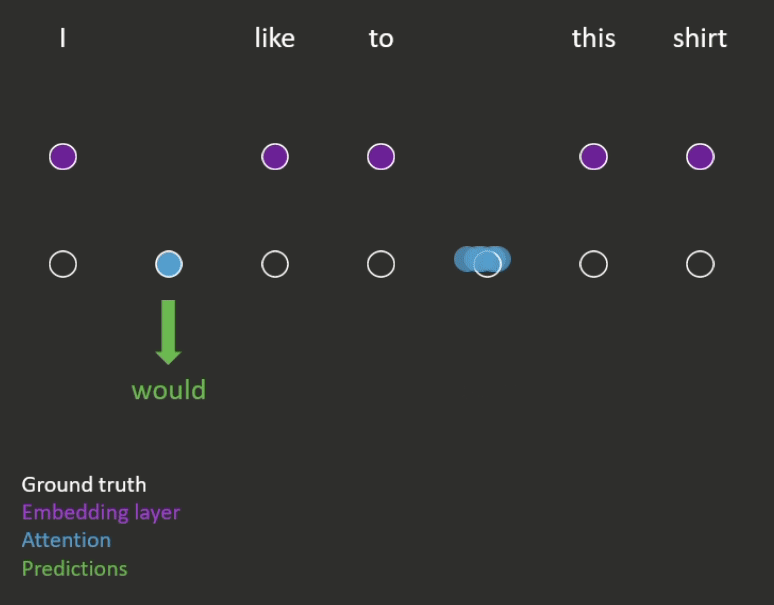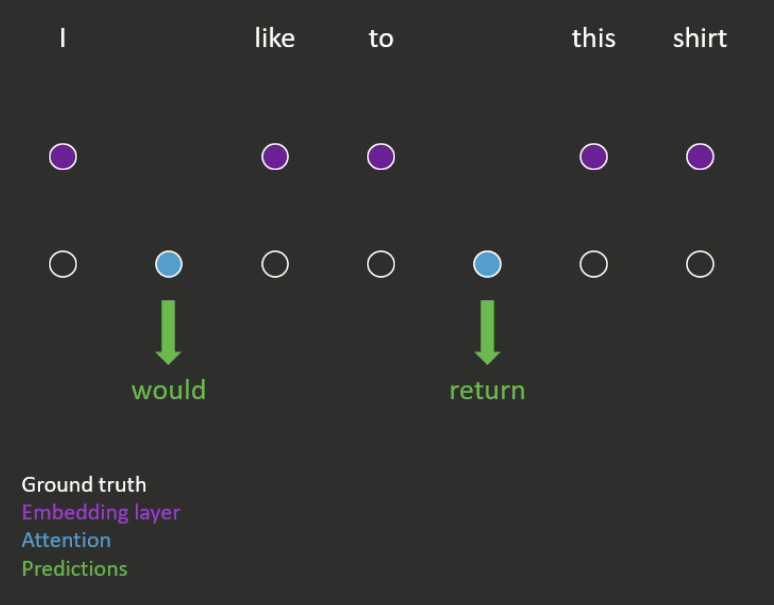
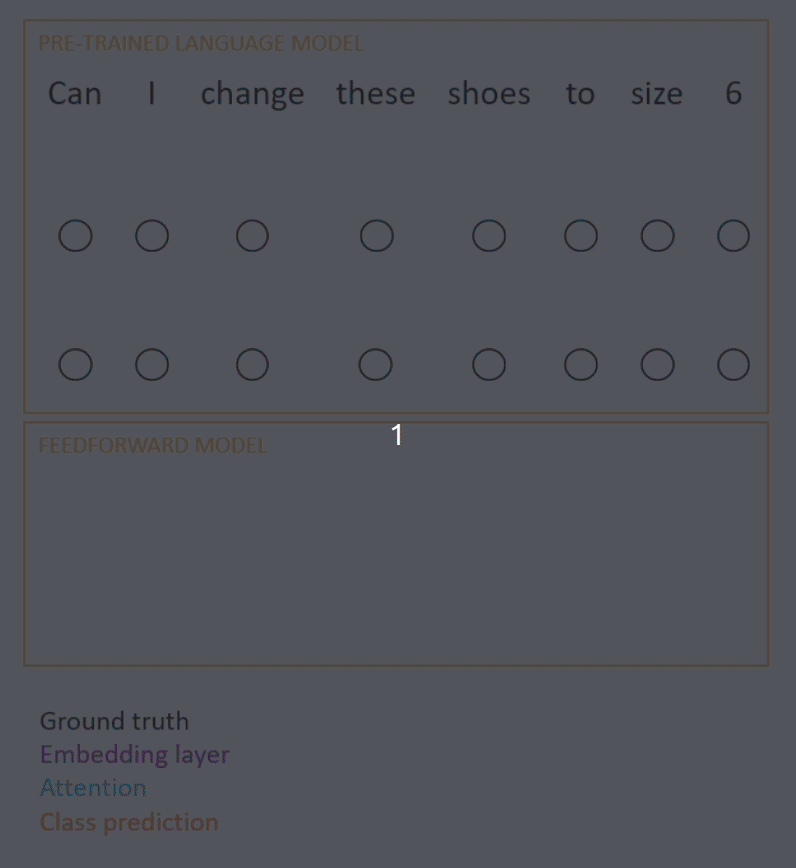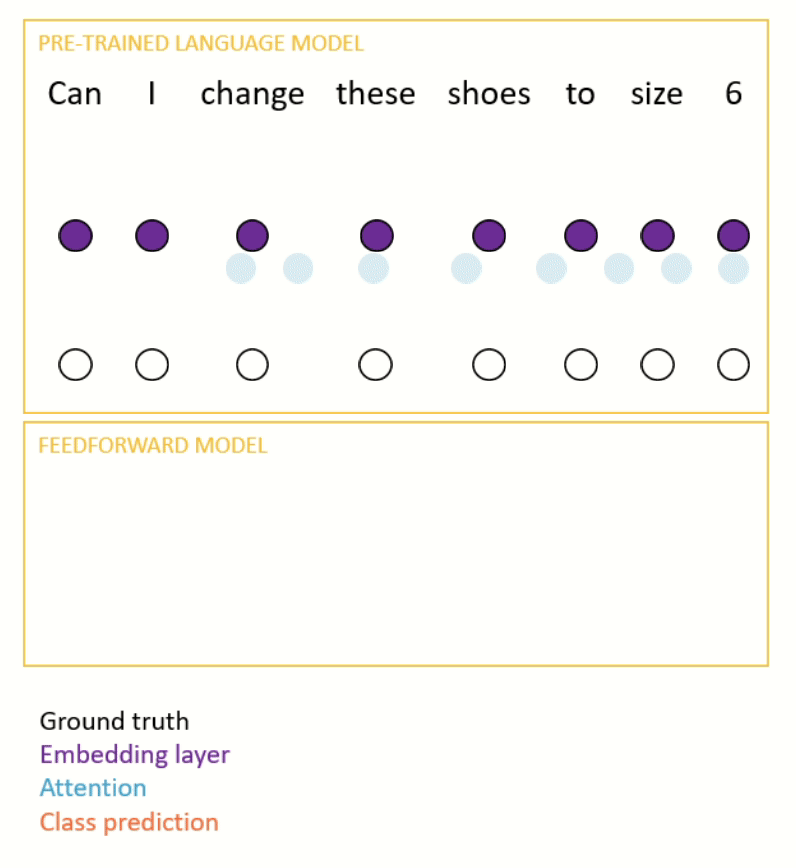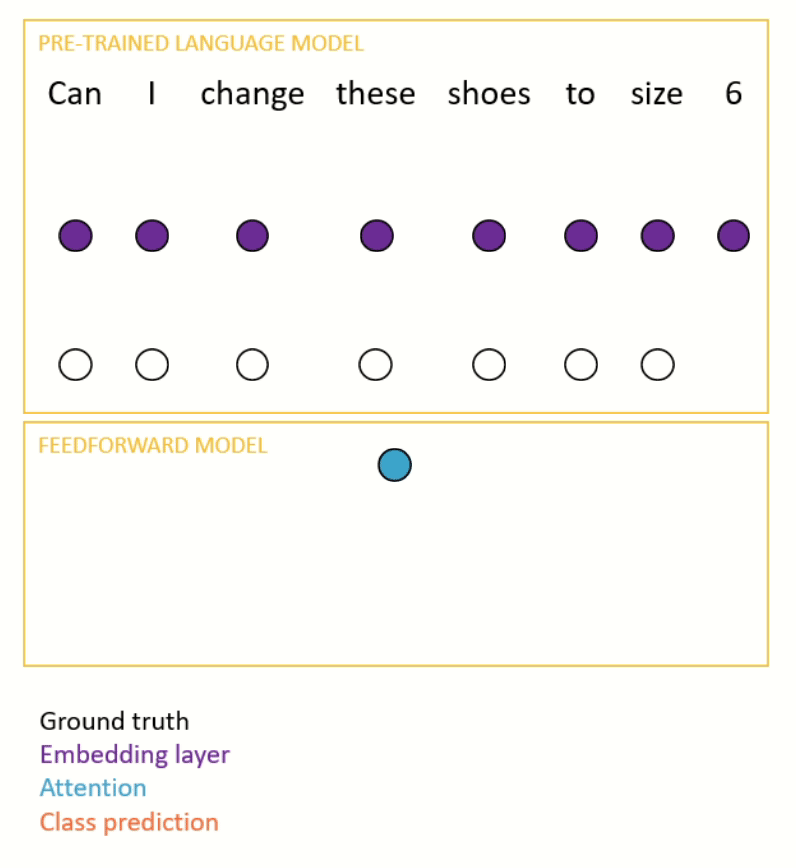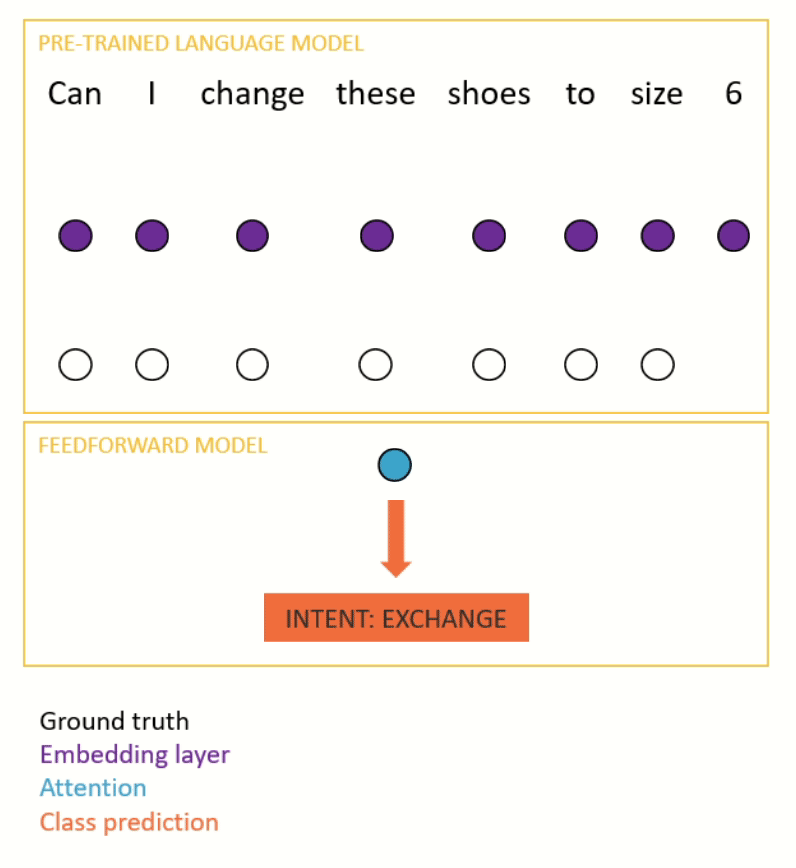
Transformers work by first encoding each word in a sequence of text as a vector of numbers known as an ‘embedding’. The embedding layer is then followed by a sequence of attention layers, which are used to build the model’s internal representations of the sequence. Finally there is the prediction layer, whose objective function depends on the type of pre-training used.
Transformers are pre-trained in an unsupervised manner. This step is most often done using one of two types of training:
- Masked language modelling (an example is shown in Figure 1)
- Some randomly chosen words are removed from the sequence, and the model is trained to predict those missing words.
- Next word prediction (an example is shown in Figure 2)
- The model has to predict each word in the sequence, conditioned on those that came before it.

Fine-tuning
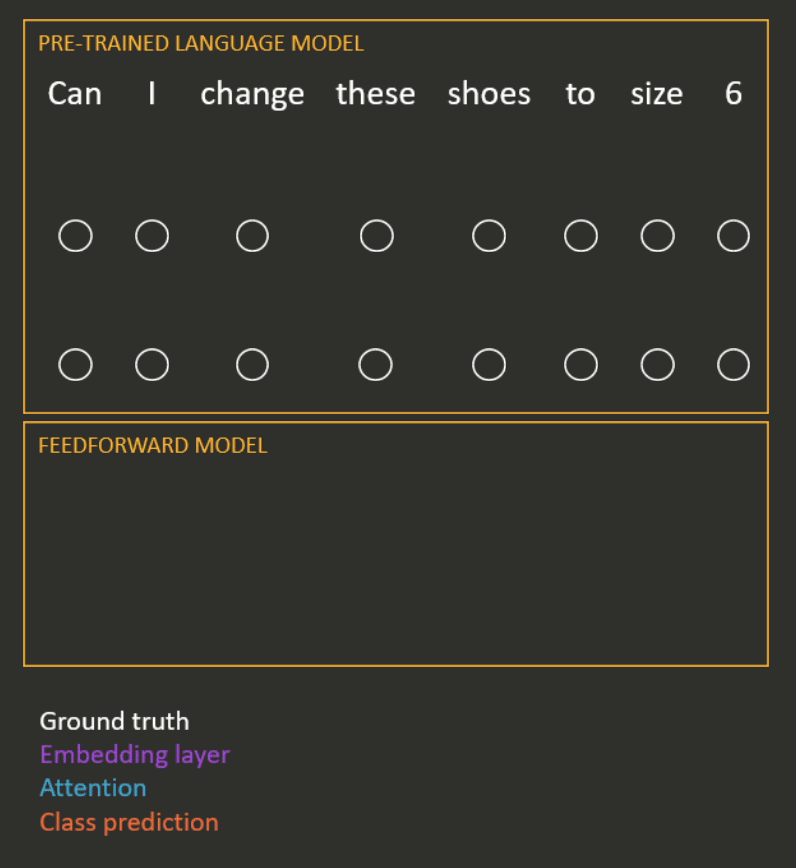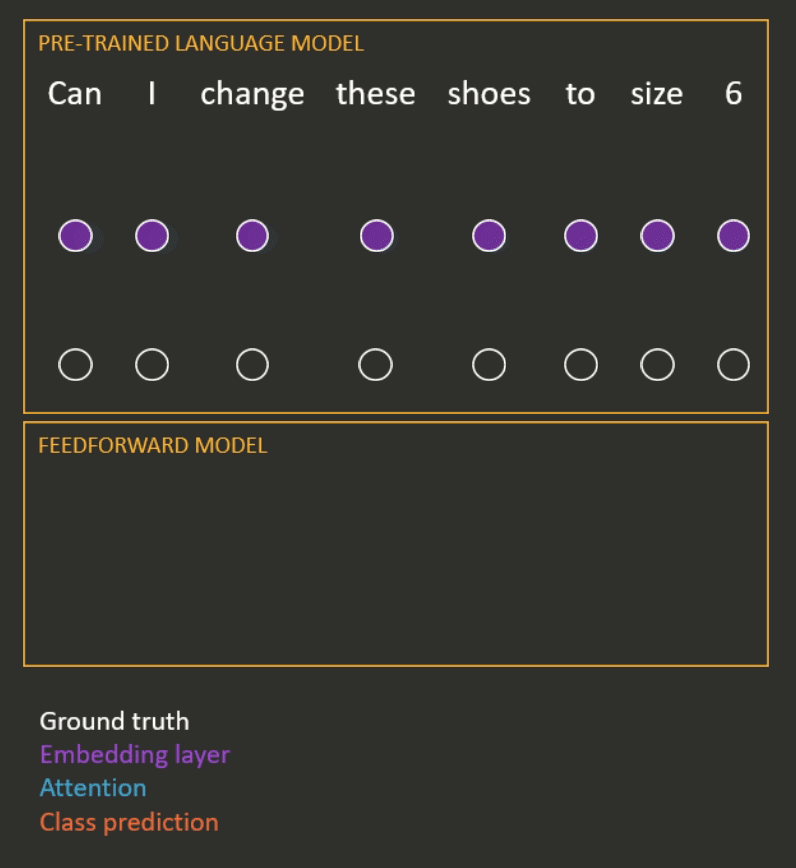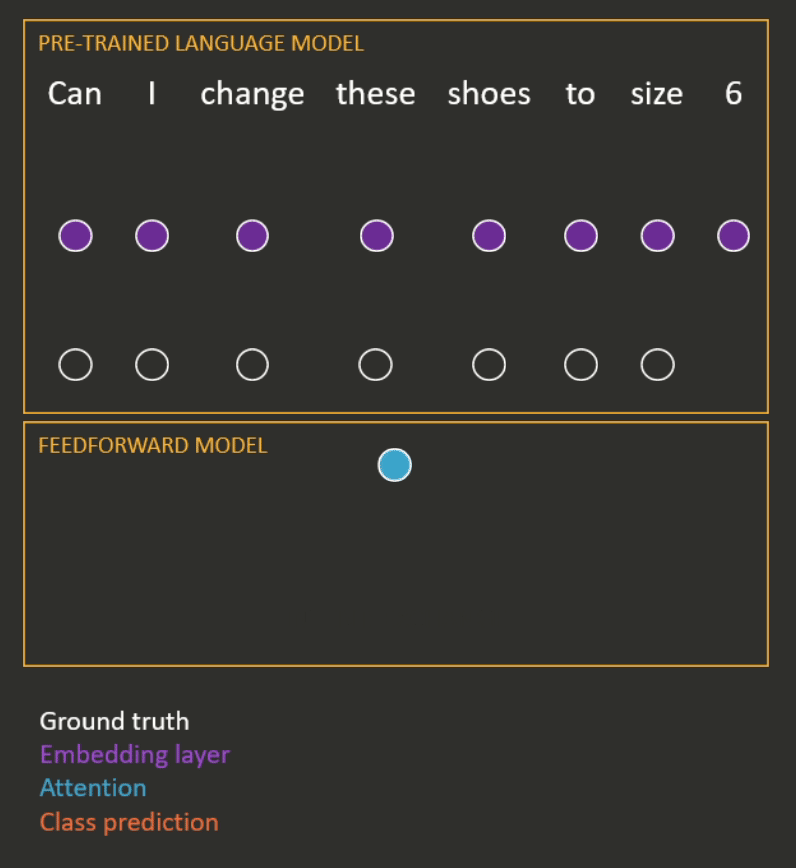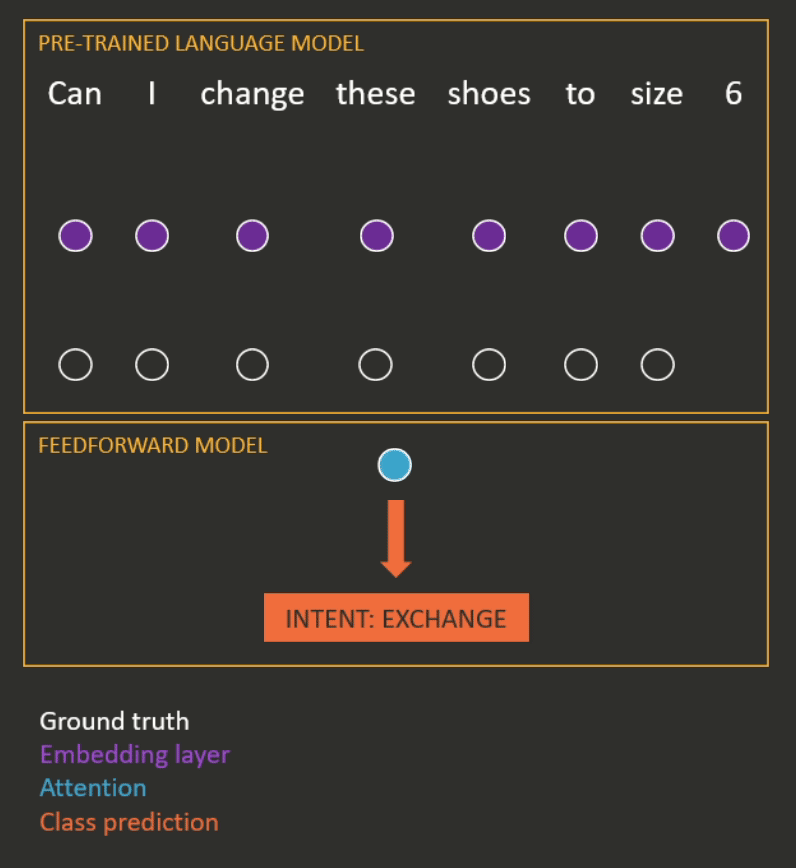
Once the model has been pre-trained, it is fine-tuned for a downstream, supervised task (e.g. intent recognition). This usually involves taking the representation at the final step of a sequence (or the mean of the representations) and passing it through a small feedforward network to make a prediction (see Figure 3 for an example). Most of the time, the parameters of both the pre-trained language model and the feedforward model are updated during the fine-tuning process.
Prompt-based learning
Suppose we have a pre-trained language model with which we want to perform a downstream task. Instead of using the representations from the language model as inputs to another model for solving the task (as described above), we could directly use its ability to model natural language by feeding it a ‘prompt’ and getting it to fill in the blanks or to complete the sequence (an example is shown in Figure 4).

It is also possible to provide examples in the prompt, to show the model how the task should be completed (see Figure 5 for an example). This is known as -shot learning, where refers to the number of examples provided. This means that Figure 4 is an example of zero-shot learning.

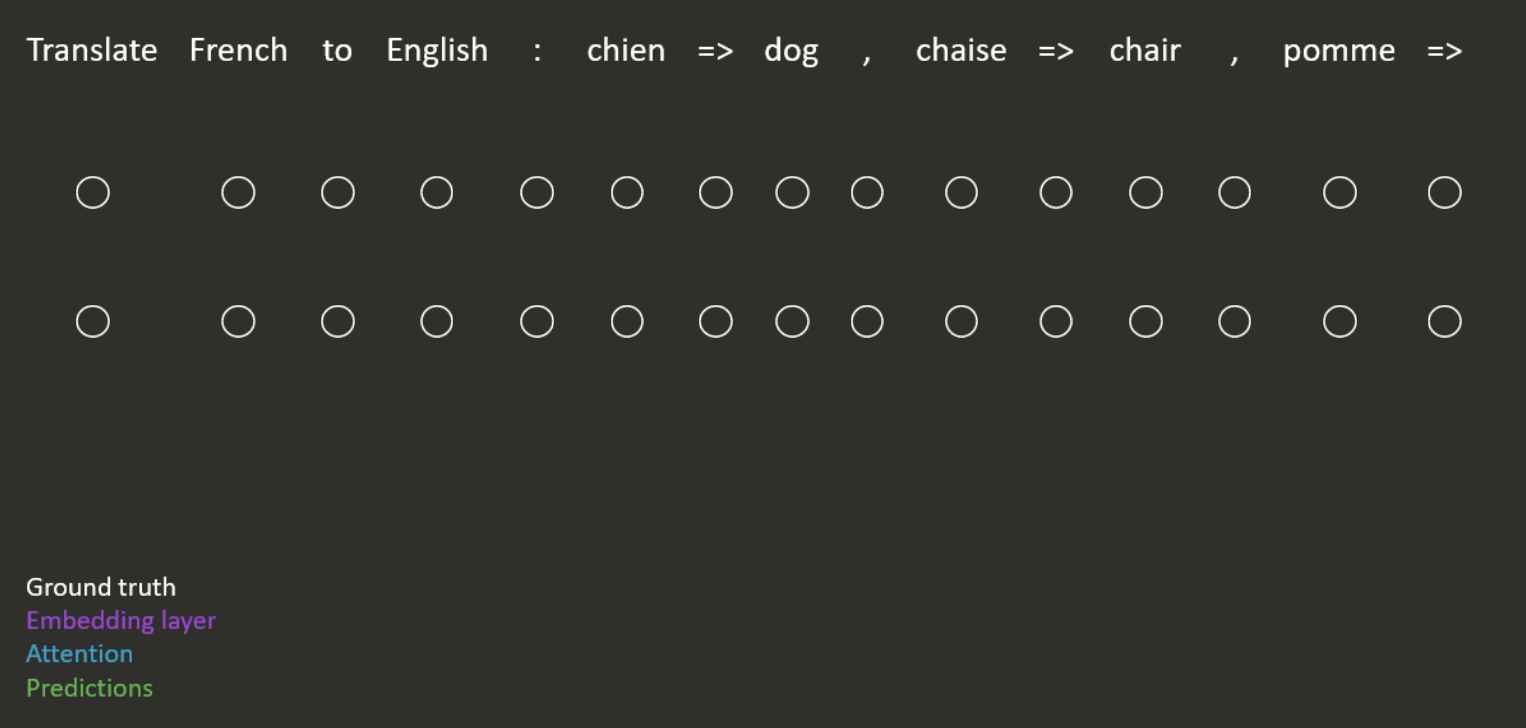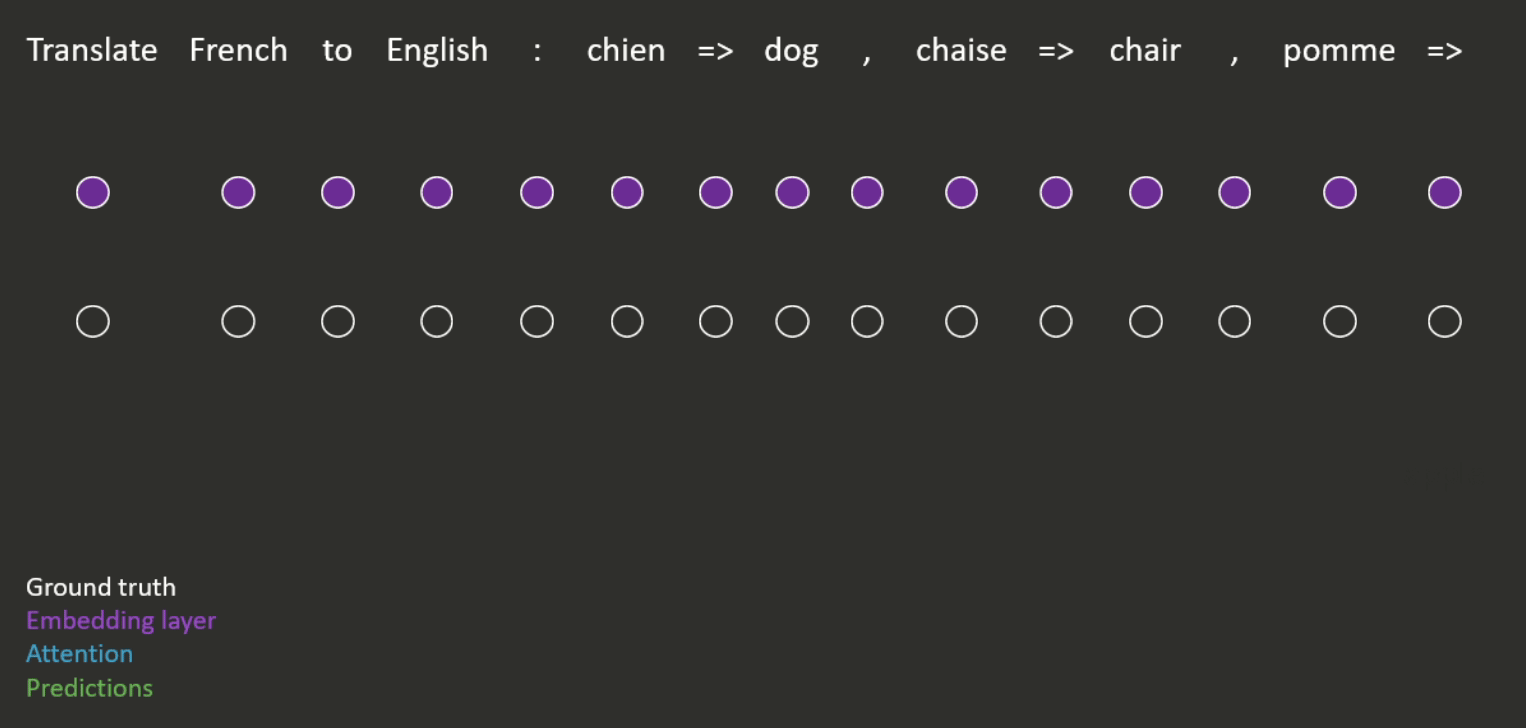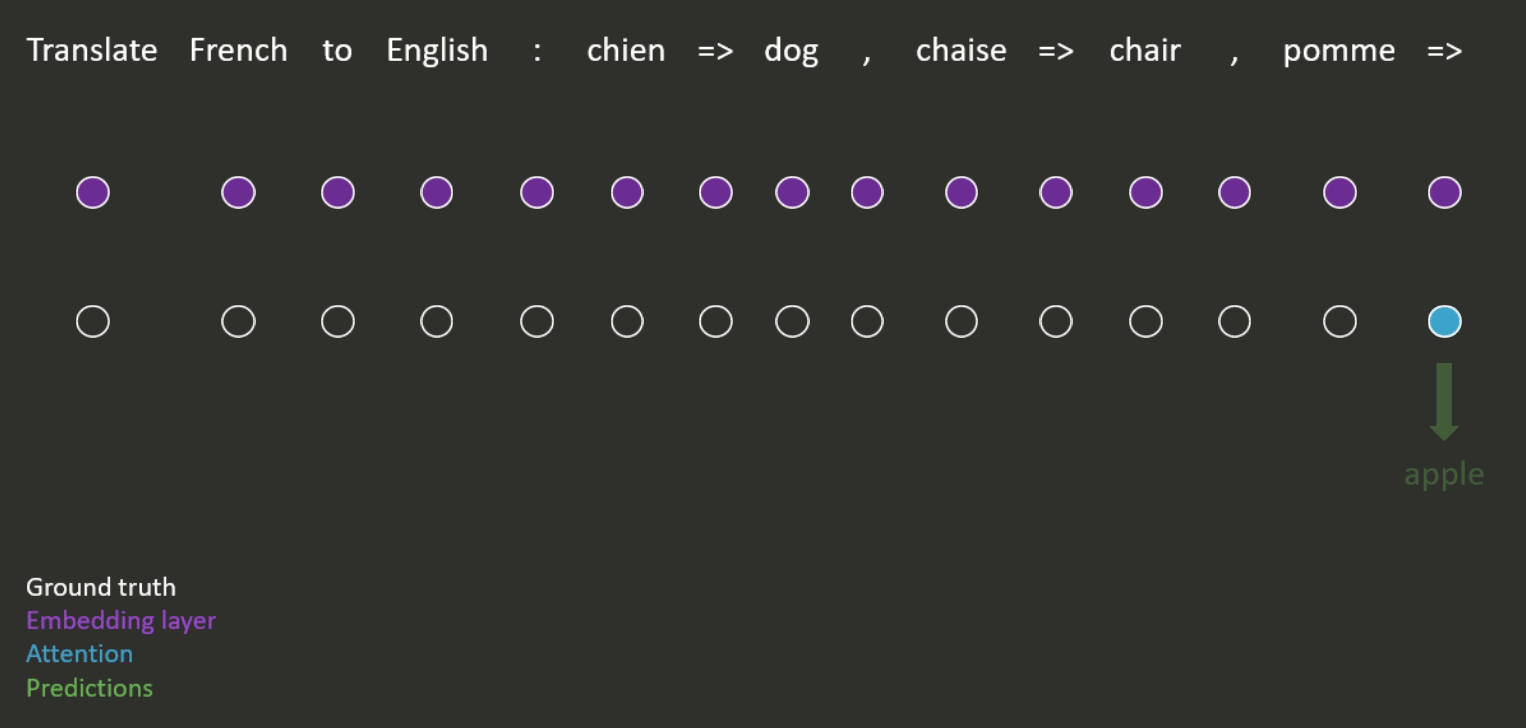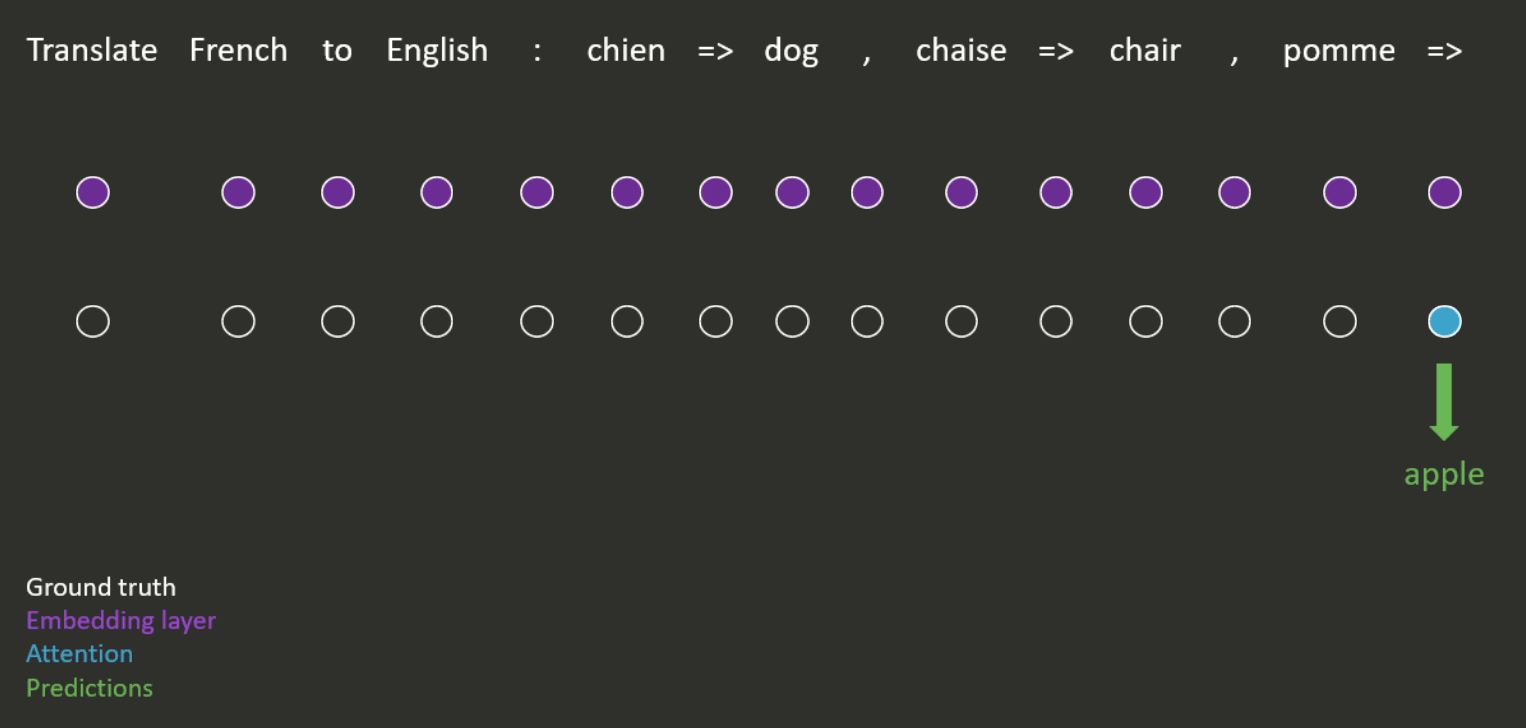
When using prompts, the model can still be fine-tuned (in the same way as described above) but this is often not necessary, as we will see below.
In the remainder of this section, we’ll review some popular prompt-based methods; see this survey paper for more comprehensive coverage.
GPT-3
GPT-3 is a large, Transformer-based language model which is trained using the next word prediction objective on a filtered version of the Common Crawl dataset. As well as being famous for generating text sequences of remarkably high quality, GPT-3 is also used to perform supervised tasks in the zero-shot, one-shot, and few-shot (10K100) settings without any fine-tuning. The authors train models of different sizes, the largest having 175 billion parameters.
Overall, GPT-3 achieves strong results in the zero-shot and one-shot settings. In the few-shot setting, it sometimes performs better than state-of-the-art models, even though they may be fine-tuned on large labelled datasets. On the vast majority of tasks, the performance of GPT-3 improves both with model size and with the number of examples shown in the prompt.
However it also struggles with certain tasks, in particular those that involve comparing multiple sequences of text. These include:
- Natural language inference
- The model is given two sentences and has to decide if the second entails, contradicts, or is neutral with respect to the first.
- Reading comprehension
- The model is given a paragraph and has to answer questions about it.
The authors hypothesise that this is because GPT-3 is trained for next word prediction, i.e. in a left-to-right (rather than bidirectional) manner.
Pattern Exploiting Training
For a given task, Pattern Exploiting Training (PET) defines a set of prompts, each with exactly one mask token, which are fed to a language model that was pre-trained with the masked language modelling objective. The PET process works as follows:
- Fine-tune a separate language model for each prompt, creating an ensemble of models for the task.
- Use this ensemble of fine-tuned models to generate ‘soft’ labels for a set of unlabelled data points, in a manner similar to knowledge distillation.
- Use these soft labels to fine-tune a final language model in the manner defined in the fine-tuning section above (i.e. not using prompts).
PET has also been extended to work with multiple mask tokens, and works well even when steps 2 and 3 above are skipped (i.e. the ensemble of fine-tuned models from step 1 is directly used as the final model). The authors use ALBERT as the base masked language model and evaluate PET in the 32-shot setting. On most tasks in the SuperGLUE benchmark, it outperforms GPT-3 while only having 0.1% as many parameters.
Prompt tuning
Unlike the methods we have looked at so far, prompt tuning does not hand-design the prompts which are fed to the model. Instead, it uses additional learnable embeddings which are directly prepended to the sequence at the embedding layer. Effectively, this skips the step of writing the prompts in natural language and instead allows the model to learn the optimal prompt directly at the embedding layer.
The prompt tuning approach (shown in Figure 6) is based on the pre-trained T5 language model. This is similar to the original Transformer, which was designed to perform translation. The T5 model has two components:
- The encoder maps the input sequence to vector representations using a self-attention mechanism, with the learnable prompt embeddings being inserted at the first layer.
- The decoder generates the text to classify the example based on the encoder representations, again using an attention mechanism.

The model is fine-tuned on a full labelled dataset for each task, but only the prompt embeddings are updated (the rest of the model, which contains the vast majority of the parameters, is frozen after pre-training). Prompt tuning significantly outperforms few-shot GPT-3, and the largest prompt-tuned model matches the performance of full fine-tuning.
Should you use prompt-based methods?
Advantages of prompt-based learning
From a practical perspective, the biggest advantage of prompt-based methods is that they generally work well with very small amounts of labelled data. For example, with GPT-3 it is possible to achieve state of the art performance on certain tasks with only one labelled example. Although it may be impractical to run a model of GPT-3’s size in a lot of settings, it is possible to outperform GPT-3 in the few-shot setting with a much smaller model by using the PET method.
From a modelling perspective, it can be argued that using prompts is a more natural way to leverage pre-trained language models for downstream tasks compared to traditional fine-tuning. This is because when using prompts, we are using the language model to generate the text that solves a task; this is also what it was trained to do in the pre-training procedure. In contrast, traditional fine-tuning (Figure 3) can be considered a less intuitive way to use language models for downstream tasks because it uses a separate model with a completely different objective function compared to the pre-training procedure.
Disadvantages of prompt-based learning
Although prompt-based methods show a lot of promise in being able to perform well on tasks with very few labelled examples, they also have certain drawbacks. Firstly, language models are prone to ‘hallucination’, i.e. they can generate text which is nonsensical, biased, or offensive. This can make such models unusable in any real-world setting. It is possible to constrain the text generated by language models, but depending on the task it may not always be possible to specify an appropriate set of restrictions while retaining performance.
Another drawback with a lot of these methods is that the prompts themselves are hand-designed. Not only is this likely to be suboptimal in terms of performance, but selecting the optimal prompt itself requires labelled validation data. PET circumvents this issue by using an ensemble of prompts, but this then requires fine-tuning a separate language model for each prompt. ‘Soft’ prompt methods (such as prompt tuning) do not require hand-designed prompts, but instead require larger training datasets.
Methods like GPT-3 described above, and the recent PaLM model, insert the labelled examples as part of the natural language prompt and don’t fine-tune the language model itself. Although this works very well in the few-shot learning setting, this can be suboptimal when there is a larger set of labelled examples available. This is because only a small number of examples can be inserted into the prompt before a maximum sequence length is reached; this limits the model to only perform few-shot learning.
Summary
In this post, we have looked at prompt-based methods—these involve directly specifying the task in natural language for a pre-trained language model to interpret and complete.
Prompting shows a lot of potential in achieving strong performance with very few labelled training examples. However, these techniques often rely on hand-designed prompts, and can be prone to hallucination, making them unsafe to use in real-world settings. Therefore, although these methods do appear to be promising, there is still a lot of research to be done to make them practical to use.
At Re:infer, we are actively researching making prompt methods safe to use, providing precise accuracy estimates and generating structured actionable data. The results of this research are coming soon.
If you want to try Re:infer at your company, sign up for a free trial or book a demo.